Открытые системы, процессы стандартизации и профили стандартов
Сергей Кузнецов
1. Введение: понятие подхода Открытых Систем
Применение подхода открытых систем в настоящее время является
основной тенденцией в области информационных технологий и средств
вычислительной техники, поддерживающих эти технологии. Идеологию
открытых систем реализуют в своих последних разработках все
ведущие фирмы - поставщики средств вычислительной техники,
передачи информации, программного обеспечения и разработки
прикладных информационных систем. Их результативность на рынке
информационных технологий и систем определяется согласованной (в
пред конкурентной фазе) научно-технической политикой и реализацией
стандартов открытых систем.
Что понимается под открытыми системами?
Для рассмотрения этого вопроса воспользуемся определениями
открытых систем, которые приведены в руководстве, изданном
Французской ассоциацией пользователей UNIX (АFUU) в 1992 году.
"Открытая система - это система, которая состоит из компонентов,
взаимодействующих друг с другом через стандартные интерфейсы".
Это определение, данное одним из авторов упомянутого руководства
Жаном-Мишелем Корну, подчеркивает системный аспект (структуру
открытой системы).
"Исчерпывающий и согласованный набор международных стандартов
информационных технологий и профилей функциональных стандартов,
которые специфицируют интерфейсы, службы и поддерживающие
форматы, чтобы обеспечить интероперабельность и мобильность
приложений, данных и персонала". Это определение, данное
специалистами IЕЕЕ, подчеркивает аспект среды, которую
предоставляет открытая система для ее использования (внешнее
описание открытой системы).
Вероятно, одно достаточно полное и общепринятое определение
открытых систем еще не сформировалось. Однако сказанного выше уже
достаточно, чтобы можно было рассмотреть общие свойства открытых
систем и выяснить существо связанных с ними проблем.
Общие свойства открытых систем обычно формируются следующим
образом:
расширяемость/масштабируемость -extensibility/scalability,
мобильность (переносимость) - portalility,
интероперабельность (способность к взаимодействию с другими
системами) - interoperability,
дружественность к пользователю, в т.ч. - легкая управляемость -
driveability.
Эти свойства, взятые по отдельности, были свойственны и
предыдущим поколениям информационных систем и средств
вычислительной техники. Новый взгляд на открытые системы
определяется тем, что эти черты рассматриваются в совокупности,
как взаимосвязанные, и реализуются в комплексе.
2. Архитектура Открытых Систем
Понятие "система" носит двоякий характер. С одной стороны, по
общему определению, система - это совокупность взаимодействующих
элементов (компонентов), аппаратных и/или программных. С другой
стороны, система может выступать в качестве компонента другой,
более сложной системы, которая в свою очередь может быть
компонентом системы следующего уровня.
В связи с этим нужно уточнить представление об архитектуре систем
и средств, как внешнем их описании (reference model) с точки
зрения того, кто ими пользуется. Архитектура открытой системы,
таким образом, оказывается иерархическим описанием ее внешнего
облика и каждого компонента с точки зрения:
пользователя (пользовательский интерфейс),
проектировщика системы (среда проектирования),
прикладного программиста (системы и инструментальные средства
/среды программирования),
системного программиста (архитектура ЭВМ),
разработчика аппаратуры (интерфейсы оборудования).
Предлагаемый взгляд на архитектуру открытых систем вытекает из
указанной выше необходимости комплексной реализации общих свойств
открытости и является расширением принятого понятия об
архитектуре ЭВМ по Г.Майерсу.
Для примера рассмотрим архитектурное представление системы
обработки данных, состоящей из компонентов четырех областей:
пользовательского интерфейса (соответственно точкам зрения всех
указанных выше групп), средств обработки данных, средств
представления и хранения данных, средств коммуникаций.
Для этого
представления требуется использовать три уровня описаний: среды,
которая представляется системой, операционной среды (системы), на
которую опираются прикладные компоненты, и оборудования. Каждый
из этих уровней разделен для удобства на два подуровня
().
Уровень среды для конечного пользователя (user environment)
характеризуется входными и выходными описаниями (генераторы форм
и отчетов), языками проектирования информационной модели
предметной области (языки 4GL), функциями утилит и библиотечных
программ и прикладным уровнем среды коммуникаций, когда требуются
услуги дистанционного обмена информацией. На этом же уровне
определена среда (инструментарий) прикладного программирования
(appliсation environment): языки и системы программирования,
командные языки (оболочки операционных систем), языки запросов
СУБД, уровни сессий и представительный среды коммуникаций.
На уровне операционной системы представлены компоненты
операционной среды, реализующие функции организации процесса
обработки, доступа к среде хранения данных, оконного интерфейса,
а также транспортного уровня среды коммуникаций. Нижний
подуровень операционной системы - это ее ядро, файловая система,
драйверы управления оборудованием, сетевой уровень среды
коммуникаций.
На уровне оборудования легко видеть привычные разработчикам ЭВМ
составляющие архитектуры аппаратных средств:
система команд процессора (процессоров),
организация памяти,
организация ввода-вывода и т.д.,
а также физическую реализацию в виде:
системных шин,
шин массовой памяти,
интерфейсов периферийных устройств,
уровня передачи данных,
физического уровня среды хранения.
Представленный взгляд на архитектуру открытой системы обработки
данных относится к одно-машинным реализациям, включенным в сеть
передачи данных для обмена информацией. Понятно, что он может
быть легко обобщен и на многопроцессорные системы с разделением
функций, а также на системы распределенной обработки данных.
Поскольку здесь явно выделены компоненты, составляющие систему,
можно рассматривать как интерфейсы взаимодействия этих
компонентов на каждом из указанных уровней, так и интерфейсы
взаимодействия между уровнями.
Описания и реализации этих интерфейсов могут быть предметом
рассмотрения только в пределах данной системы. Тогда свойства ее
открытости проявляются только на внешнем уровне. Однако значение
идеологии открытых систем состоит в том, что она открывает
методологические пути к унификации интерфейсов в пределах
родственных по функциям групп компонентов для всего класса систем
данного назначения или всего множества открытых систем.
Стандарты интерфейсов этих компонент (де-факто или принятые
официально) определяют лицо массовых продуктов на рынке. Область
распространения этих стандартов являются предметом согласования
интересов разных групп участников процесса информатизации -
пользователей, проектировщиков систем, поставщиков программных
продуктов и поставщиков оборудования.
Выше был рассмотрен пример архитектуры открытых систем,
реализующих технологию обработки данных. Можно было бы
представить аналогичным образом открытые системы для всех классов
информационных технологий: обработки текстов, изображений, речи,
машинной графики. Особенно актуально проработать подходы открытых
систем для мультимедиа-технологий, сочетающих несколько разных
представлений информации. Как известно, за рубежом эти работы
проводятся различными ассоциациями и консорциумами
заинтересованных фирм и академических организаций и
международными организациями по стандартизации. К сожалению,
российские специалисты в этих работах до сих пор в лучшем случае
играют роль наблюдателей.
3. Преимущества идеологии открытых систем
Конечно, подход открытых систем пользуется успехом только потому,
что обеспечивает преимущества для разного рода специалистов,
связанных с областью компьютеров.
Для пользователя открытые системы обеспечивают следующее:
новые возможности сохранения сделанных вложений благодаря
свойствам эволюции, постепенного развития функций систем, замены
отдельных компонентов без перестройки всей системы;
освобождение от зависимости от одного поставщика аппаратных или
программных средств, возможность выбора продуктов из предложенных
на рынке при условии соблюдения поставщиком соответствующих
стандартов открытых систем;
дружественность среды, в которой работает пользователь,
мобильность персонала в процессе эволюции системы;
возможность использования информационных ресурсов, имеющихся в
других системах (организациях).
Проектировщик информационных систем получает:
возможность использования разных аппаратных платформ;
возможность совместного использования прикладных программ,
реализованных в разных операционных системах;
развитые 4средства 0инструментальных сред, поддерживающих
проектирование;
возможности использования готовых программных продуктов и
информационных ресурсов.
Разработчики общесистемных программных средств имеют:
новые возможности разделения труда, благодаря повторному
использованию программ(reusability);
развитые инструментальные среды и системы программирования;
возможности модульной организации программных комплексов
благодаря стандартизации программных интерфейсов.
Это последнее свойство открытых систем позволяет пересмотреть
традиционно сложившееся дублирование функций в разных программных
продуктах, из-за чего системы, интегрирующие эти продукты,
непомерно разрастаются по объему, теряют эффективность. Известно,
что в той же области обработки данных и текстов многие продукты,
предлагаемые на рынке (текстовые редакторы, настольные
издательства, электронные таблицы, системы управления базами
данных) по ряду функций дублируют друг друга, а иногда и
подменяют функции операционных систем. Кроме того, замечено, что
в каждой новой версии этих продуктов размеры их увеличиваются на
15%.
В распределенных системах, содержащих несколько рабочих мест на
персональных компьютерах и серверов в локальной сети,
избыточность программных кодов из-за дублирования возрастает
многократно.
Идеология и стандарты открытых систем позволяют
по- новому взглянуть на распределение функций между программными
компонентами систем и значительно повысить тем самым
эффективность. Частично этот подход обеспечивает компенсацию
затрат ресурсов, которые приходится платить за преимущества
открытых систем относительно закрытых систем, ресурсы которых в
точности соответствуют задаче, решаемой системой.
4. Открытые Системы и объектно-ориентированный подход
В связи с применением подхода открытых систем весьма
перспективным направлением представляется
объектно-ориентированный стиль проектирования и программирования.
Объектно-ориентированное программирование - это относительно
новый подход к разработке программных систем. Этот подход
строится на следующих основных принципах:
данные и процедуры объединяются в программные объекты;
для связи объектов используется механизм посылки сообщения;
объекты с похожими свойствами объединяются в классы;
объекты наследуют свойства других объектов через иерархию
классов.
Объектно-ориентированные системы обладают следующими 4основными
свойствами:
Инкапсуляция (скрытие реализации) - данные и процедуры объекта
скрываются от внешнего пользователя, и связь с объектом
ограничивается набором сообщений, которые "понимает" объект.
Полиморфизм (многозначность сообщений) - одинаковые сообщения
по-разному понимаются разными объектами, в зависимости от их
класса.
Динамическое (позднее) связывание - значение имени (область
памяти для данных или текст программы для процедур) становится
известным только во время выполнения программы.
Абстрактные типы данных - объединение данных и операций для
описания новых типов, позволяющие использовать новые типы наравне
с уже существующими.
Наследование - позволяет при создании новых объектов
использовать свойства уже существующих объектов, описывая заново
только те свойства, которые отличаются.
Заметим, что основные свойства открытых систем хорошо
поддерживаются объектно-ориентированным подходом к реализации
системы (). Рассмотрим отдельные аспекты этой поддержки.
Мобильность
Инкапсуляция позволяет хорошо скрыть машинно-зависимые части
системы, которые должны быть реализованы заново при переходе на
другую платформу. При этом гарантируется, что остальная часть
системы не потребует изменений.
При реализации новых машинно-зависимых частей многое может быть
взято из уже существующей системы благодаря механизму
наследования.
Расширяемость
Наследование позволяет сэкономить значительные средства при
расширении системы, поскольку многое не нужно создавать заново, а
некоторые новые компоненты можно получить, лишь слегка изменив
старые. Кроме повторного использования, увеличивается также
надежность, поскольку используются уже отлаженные компоненты.
Возможность конструирования абстрактных типов данных для создания
новых средств - обеспечивается самим понятием класса,
объединяющего похожие объекты с одинаковым набором операций.
Интероперабельность
Способность системы взаимодействовать с другими системами хорошо
поддерживается принципом посылки сообщения и соответствующими
понятиями полиморфизма и динамического связывания. В сообщении
объекту (возможно удаленному) передается имя действия, которое
должно быть им выполнено, и некоторые дополнительные аргументы
сообщения. Как это действие выполнять - знает и решает только сам
объект - получатель сообщения. От него только требуется выдать в
ответ результат. Совершенно очевидно, что разные объекты будут
по-разному реагировать на одинаковые сообщения (полиморфизм).
Кроме того, очень удобно выбирать способ реализации в последний
момент - при ответе на сообщение, в зависимости от текущего
состояния системы (динамическое связывание).
Для того, чтобы разные системы могли обмениваться сообщениями,
необходима либо единая трактовка всех типов данных, в том числе
абстрактных, либо индивидуальная процедура преобразования
сообщения для каждой пары неодинаковых взаимодействующих систем.
Простота понятия абстрактных типов данных в
объектно-ориентированных системах существенно облегчает
разработку такой процедуры.
Дружественность
Удобство взаимодействия человека с системой требует от последней
наличия всех трех вышеуказанных качеств. Мобильность необходима
ввиду быстрой смены старых и появления новых устройств, в
частности, средств мультимедиа. Расширяемость требуется для
разработки программной поддержки новых парадигм общения человека
с машиной. Интероперабельность просто рассматривает человека как
другую систему, с которой открытая система должна уметь
взаимодействовать.
5. Стандарты Открытых Систем
В настоящее время в мире существует несколько авторитетных
сообществ, занимающихся выработкой стандартов открытых систем.
Однако исторически и, по-видимому, до сих пор наиболее важной
деятельностью в этой области является деятельность комитетов
POSIX. В этом разделе мы приведем краткий обзор этой деятельности.
Первая рабочая группа POSIX (Portable Operating System Interface)
была образована в IEEE в 1985 г. на основе UNIX-ориентированного
комитета по стандартизации /usr/group (ныне UniForum). Отсюда
видна первоначальная направленность работы POSIX на
стандартизацию интерфейсов ОС UNIX. Однако постепенно тематика
работы рабочих групп POSIX (а со временем их стало несколько)
расширилась настолько, что стало возможным говорить не о
стандартной ОС UNIX, а о POSIX-совместимых операционных средах,
имея в виду любую операционную среду, интерфейсы которых
соответствуют спецификациям POSIX.
Сейчас функционируют и регулярно выпускают документы следующие
рабочие группы POSIX.
POSIX 1003.0. Рабочая группа, выпускающая "Руководство по
POSIX-совместимым средам Открытых Систем". Это руководство
содержит сводную информацию о работе и текущем состоянии
документов всех других рабочих групп POSIX, а также других
тематически связанных организаций, связанных со стандартизацией
интерфейсов Открытых Систем.
POSIX 1003.1. Интерфейсы системного уровня и их привязка к языку
Си.
В документах этой рабочей группы определяются обязательные
интерфейсы между прикладной программой и операционной системой. С
выпуска первой версии этого документа началась работа POSIX, и он
в наибольшей степени связан с ОС UNIX, хотя в настоящее время
интерфейсы 1003.1 поддерживаются в любой операционной среде,
претендующей на соответствие принципам Открытых Систем. Заметим,
что несмотря на очевидную важность 1003.1, в документе
отсутствуют спецификации многих важных интерфейсов, в частности,
интерфейсы системных вызовов, обеспечивающих межпроцессные
взаимодействия.
POSIX 1003.2. Shell и утилиты. Рабочая группа специфицирует
стандартный командный язык shell, основанный главным образом на
Bourne shell, но включающий некоторые черты Korn shell. Кроме
того, в документах этой рабочей группы специфицировано около 80
утилит, которые можно вызывать из процедур shell или прямо из
прикладных программ. В документах серии 1003.2a описываются
дополнительные средства, позволяющие пользователям работать с
системой с помощью только ASCII-терминалов.
POSIX 1003.3. Общие методы проверки совместимости с POSIX. Целью
рабочей группы является разработка методологии проверки
соответствия реализаций стандартам POSIX. Документы рабочей
группы используются в различных организациях при разработке
тестовых наборов.
POSIX 1003.4. Средства, предоставляемые системой для прикладных
программ реального времени. В соответствии с определением 1003.4,
системой реального времени считается система, обеспечивающая
предсказуемое и ограниченное время реакции. Работа ведется в трех
секциях: файловые системы реального времени, согласованные
многопотоковые (multithread) архитектуры, а также в секции,
занимающейся такими вопросами, как семафоры и сигналы.
POSIX 1003.5. Привязка языка Ада к стандартам POSIX. В документах
этой рабочей группы определяются правила привязки программ,
написанных на языке Ада, к системным средствам, определенным в
POSIX 1003.1.
POSIX 1003.6. Расширения POSIX, связанные с безопасностью.
Разрабатываемый набор стандартов базируется на критериях
министерства обороны США и будет определять безопасную среду
POSIX.
POSIX 1003.7. Расширения, связанные с администрированием системы.
Стандарт, разрабатываемый рабочей группой, будет определять общий
интерфейс системного администрирования, в частности, разнородных
сетей. Отправной точкой является модель OSI.
POSIX 1003.8. Прозрачный доступ к файлам. Будут обеспечены
интерфейсы и семантика прозрачного доступа к файлам,
распределенным в сети. Работа основывается на анализе
существующих механизмов: NFS, RFS, AFS и FTAM.
POSIX 1003.9. Привязка языка Фортран. Определяются правила
привязки прикладных программ, написанных на языке Фортран, к
основным системным средствам.
POSIX 1003.10. Общие черты прикладной среды суперкомпьютеров
(Application Environment Profile - AEP).
POSIX 1003.11. Общие черты прикладной среды обработки транзакций
(On-line Transaction Processing Application Environment - OLTP).
POSIX 1003.12. Независимые от протоколов коммуникационные
интерфейсы. Разрабатываются два стандартных набора интерфейсов
для независимых от сетевых протоколов коммуникаций
"процесс-процесс". Результаты должны обеспечивать единообразную
работу с TCP/IP, OSI и другими системами коммуникаций.
POSIX 1003.13. Общие черты прикладных сред реального времени.
POSIX 1003.14. Общие черты прикладных сред мультипроцессоров.
Помимо прочего, должны быть предложены соответствующие расширения
стандартов других рабочих групп.
POSIX 1003.15. Расширения, связанные с пакетной обработкой.
Определяются интерфейсы пользователя и администратора и сетевые
протоколы для пакетной обработки.
POSIX 1003.16. Привязка языка Си. Задача проекта, выполняемого
реально рабочей группой 1003.1, состоит в выработке правил
привязки международного стандарта языка Си (ISO 9989) к
независимым от языка интерфейсам, определяемым POSIX 1003.1-1990
(ISO 9945-1).
POSIX 1003.17. Справочные услуги и пространство имен. Задачей
рабочей группы является анализ и выработка рекомендаций по работе
со справочниками и пространством имен в контексте X.500.
POSIX 1003.18. Общие черты среды POSIX-платформы. В одном
документе должны быть специфицированы основные характеристики
интерактивной многопользовательской прикладной платформы,
соответствующей стандартам POSIX. Работа выполняется группой
1003.1.
6. Профили стандартов Открытых Систем
Интеграция компонентов в открытой системе должна следовать
профилям стандартов на интерфейсы этих компонент.
Профиль составляют набор согласованных стандартов интерфейсов
компонентов на каждом уровне системы (как было показано выше на
примере системы обработки данных) и обеспечивают их
совместимость.
Для определенности рассмотрения интерфейсов компонент и
проведения необходимых анализов их реализуемости можно
использовать модель среды открытых систем MUSIC, разработанную
центральным агентством по компьютерам и телекоммуникациям (ССТА)
Великобритании. Эта модель используется в руководстве фирмы
Digital Equipment по построению открытых систем. Модель MUSIC
содержит пять групп компонентов, из которых строятся открытые
системы:
управление (Management) - функции системной администрации,
безопасности, управления ресурсами, конфигурацией, сетевое
управление;
пользовательский интерфейс (User Interface) - интерфейс
пользователя с прикладными программами и со средой разработки
приложений;
системные интерфейсы для программ (Service Interface for
Programs) - интерфейсы между прикладными программами и между
прикладными программами и операционной системой, в частности API
(Application Programs Interface);
форматы информации и данных;
интерфейсы коммуникаций.
Европейская рабочая группа по открытым системам (EWOS) предложила
шесть профилей стандартов составляющих среды открытых систем:
среда рабочих станций,
среда серверов процессов,
среда серверов данных,
среда транзакций,
среда реального времени,
среда суперкомпьютеров.
Кроме указанного набора профилей по классам аппаратно-программных
средств существует необходимость формирования вертикальных
профилей открытых систем, ориентированных на
проблемно-ориентированные области применения. В качестве таких
первоочередных областей применения открытых систем в России можно
назвать:
интегрированные производственные системы,
информационные системы (системы информационного обслуживания) с
удаленным доступом к ресурсам,
системы автоматизации учреждений,
системы автоматизации банков,
системы автоматизации научных исследований,
системы передачи данных.
7. Заключение
Подход открытых систем обеспечивает слишком много преимуществ,
чтобы можно было игнорировать его в России. Однако до сих пор
все, что делается по этому поводу, основывается главным образом
на энтузиазме. Просматриваются, как минимум, два необходимых и
безотлагательных действия.
Во-первых, необходимо выполнить ряд научных проектов, связанных с
анализом реализуемости международных стандартов в наших условиях,
выбором и разработкой профилей стандартов открытых систем по
областям их применения, как технической основы информационной
инфраструктуры общества.
Во-вторых, требуется выработать и согласовать стандарты
интерфейсов на разработку или приобретение аппаратных и
программных средств.
Таблица 1
| Интерфейсы | Средства обработки данных | Представление и хранение данных | Коммуникации |
| Генераторы форм и отчетов | Утилиты и библиотеки | Языки программирования 4GL | OSI. Прикладной уровень |
| Языки программные и командные языки (оболочки) | Прикладные программы | Языки запросов СУБД | OSI. Уровни сессий и представительный |
| Средства оконного интерфейса | Верхний уровень ОС (организация процесса обработки) | Средства доступа к среде хранения | OSI. Транспортный уровень |
| Драйверы | Ядро операционной системы | Файловая система | OSI. Сетевой уровень |
| Системные интерфейсы (в т.ч. организация ввода-вывода) | Процессоры (система команд) | Организация памяти | OSI. Уровень передачи данных |
| Периферийные устройства | Системная шина | Шины (интерфейс) массовой памяти | OSI. Физический уровень |
| Дружественность (пользователь) | Мобильность (платформы) | Расширяемость (новые функции и области применения) | Интероперабельность (другие системы, пользователь) |
| Объектное представление предметной области, наиболее удобное человеку. Сочетание всех других свойств при конструировании пользовательского интерфейса | Инкапсуляция (скрытие реализации) | Наследование, абстрактные типы данных | Полиморфизм, динамическое связывание |
Отображение IDL в языки программирования.
Различные объектно-ориентированные или объектно-неориентированные языки программирования могут получать доступ к объектам различным образом. Для объектно-ориентированных языков допускается отображение объектов, доступных ORB-у в объекты в смысле этих языков программирования. Даже для объектно-неориентированных языков декорирование настоящего представления ссылок на объекты будет полезным. Конкретное отображение IDL для языка программирования должно быть идентичным для всех реализаций ORB-ов. Отображение для языка программирования включает в себя определение специфичных для языка программирования типов данных и описания процедур доступа к объектам посредством ORB-а. Оно также включает в себя интерфейс для доступа клиента к заглушке, что может не требоваться для объектно-ориентированных языков, интерфейс динамических вызовов, скелет реализации, описание адаптеров объектов и прямой интерфейс к ORB-у.
Отображение для языка также определяет порядок взаимодействия между вызовом метода и потоками (тредами - threads) как со стороны клиента, так и со стороны реализации. Обычно обеспечивается синхронный вызов, в котором подпрограмма вызова возвращает управление при завершении выполнения запроса. Допускается определение дополнительных средств, для определения порядка передачи управления и синхронизации клиентского кода с вызовом метода объекта.
Парадокс Эпименида
Рассмотрим следующий пример:
Пусть P – это предикат «Отсутствует истинная инстанциация предиката P». Предположим, что P является допустимым предикатом (я проанализирую это предположение в следующем разделе); тогда в действительности это не только предикат, но и высказывание, поскольку в нем отсутствуют параметры. Пусть r – это отношение, соответствующее P (т.е. отношение, в теле которого содержаться те и только те кортежи, которые представляют истинные инстанциации P). Поскольку у P отсутствуют параметры, у r отсутствуют атрибуты (т.е. это отношение степени ноль), и, следовательно, оно должно быть либо TABLE_DEE, либо TABLE_DUM. Напомню, что TABLE_DEE – это единственное отношение без атрибутов и с ровно одним кортежем (0-кортежем), а TABLE_DUM – это единственное отношение без атрибутов и без кортежей [5]. Предположим, что r – это TABLE_DEE. Тогда интерпретация (наличие в r единственного кортежа) состоит в том, что P является истинным – что, по определению, означает отсутствие истинных инстанциаций P, и, следовательно, r не должно содержать никаких кортежей (т.е. должно быть TABLE_DUM). Наоборот, предположим, что r – это TABLE_ DUM. Тогда интерпретация (того факта, что в r нет ни одного кортежа) состоит в том, что P является ложным – что, по определению, означает наличие хотя бы одной (на самом деле, ровно одной) истинной инстанциации P, и, следовательно, r должно содержать хотя бы один (на самом деле, ровно один) кортеж (т.е. должно быть TABLE_ DEE).
Вероятно, вы уже поняли, что этот пример воспроизводит в реляционной форме известный парадокс Эпименида. И конечно, корнем проблемы является ссылка на самого себя: предикат P ссылается сам на себя.
На тот случай, если вам неудобно полагаться на аргументы, основанные на специальных отношениях TABLE_DEE и TABLE_DUM, позвольте привести другой пример, иллюстрирующий тот же случай. Этот пример представляет собой существенно упрощенный вариант примера, приведенного Дэвидом Макговерном (David McGoveran) и опубликованного мной в колонке журнала DBP&D [2]. Пусть r – это отношение с единственным атрибутом N типа INTEGER, и пусть предикатом для r является «Мощность r есть N». Если r пусто, то мощность r равна нулю, и, следовательно, в r должен входить кортеж t = TUPLE {N 0}, и поэтому r не должно быть пусто. Но если кортеж t = TUPLE {N 0} действительно входит в r, то r не является пустым, и, следовательно, кортеж t не должен входить в r. То есть снова имеется некоторая разновидность того же парадокса.
Параметры.
Параметр характеризуется режимом передачи и своим типом. Режим определяет, должно ли передаваться значение параметра от клиента к серверу (in), от сервера к клиенту (out) или в обоих направлениях (inout).
Возвращаемое значение. Если есть возвращаемое значение, то оно рассматривается как параметр типа out. Исключения. Исключение свидетельствует о том, что операция не была успешно выполнена. Исключение может содержать дополнительную информацию, специфичную для конкретного исключения. Контекст. Контекст запроса обеспечивает передачу дополнительной, специфичной для операции информации, которая может повлиять на выполнение запроса.
Параметры запросов определяются их позицией. Параметры могут быть входные, выходные и входные и выходные одновременно. Как результат запрос может возвратить одно значение, как, впрочем, и любые выходные параметры. В случае возникновения исключения значение всех выходных параметров не определено.
Параметры могут задаваться пользователем либо вычисляться автоматически из значений других параметров, если в качестве значения параметра поставляется запрос. Это может быть сделано при проведении наблюдения заранее описанного типа, если в описании параметра ему поставлен в соответствие какой-либо запрос, либо непосредственно в момент проведения наблюдения.
Запрос представляет собой процедуру, которая осуществляет доступ к данным и может поставлять одно значение или множество значений. В простейшем случае запрос представляет собой арифметическое выражение.
Название "вычисляемый" для параметров, с которыми ассоциирован какой-либо запрос, используется по традиции. Такие параметры следует назвать скорее вычислимыми, поскольку при проведении наблюдения такому параметру может быть присвоено любое значение, и тогда формула для его вычисления использоваться не будет.
Вычисляемый параметр может зависеть или не зависеть от других параметров и времени (возможно, транзитивно). В определении формул для вычисляемых параметров запрещены циклические зависимости. В качестве времени для всех вычисляемых параметров в данном наблюдении фиксируется момент начала наблюдения (см. раздел Операции).
Вычисляемый параметр может исполняться только один раз при проведении наблюдения либо каждый раз при обращении к нему. В связи с этим параметры можно разделить на статические и динамические.
Статические параметры вычисляются при проведении наблюдения один раз с использованием некоторого запроса. В дальнейшем их значение не изменяется. Подобные запросы должны поставлять значение и их исполнение не должно вызывать побочных эффектов. Это означает, что процедура вычисления статического параметра не может инициировать проведения других наблюдений либо требовать активности со стороны пользователя. Статический параметр не может также зависеть от динамических параметров.
Если параметр определен как статический, то в системе сохраняется его значение, а не формула, по которой он вычислялся.
Динамический параметр вычисляется каждый раз при обращении к этому параметру. Значением динамического параметра является запрос. В частности, это может быть просто ссылка на текущее значение некоторого параметра другого объекта.
На практике часто встречаются ситуации, когда совокупность объектов и наблюдений над ними разбиваются на группы - по каким-то условиям или произвольно. Эти группы могут различаться природой объектов, значением параметров, ожидаемым поведением. В любом случае, объекты разбиваются на категории, классы, группы. Обычно эта цель достигается либо типизацией объектов, либо дополнительными средствами, такими, как индексные файлы, размещение объектов в разных файлах, объединение объектов в наборы, множества, коллекции и т.д.
Как правило, по условию членства объектов в них различают ручные и автоматические группы. Это связано с тем, что присутствием объектов в группе можно управлять вручную или автоматически. В первом случае членством объекта в группе управляет пользователь с помощью специальных средств. Во втором случае присутствие объекта в группе определяется автоматически на основе условия, определенного через параметры объекта. По существу, автоматическая группа представляет собой запрос, возвращающий не один, а множество объектов.
Для того чтобы далее оперировать с группой объектов как с единым целым, необходимо ввести соответствующий тип данных.
Над значением типа "группа" можно выполнять ряд специфических операций: индексация и выделение подмножества, теоретико-множественные операции, добавление и удаление объектов, перебор, поиск, статистические процедуры и т.д. К группе могут применяться и скалярные операции - в этом случае они применяются к каждому элементу группы.
Эффективность работы с этим типом данных в значительной степени определяется реализацией. Если, например, для каждого нового наблюдения происходит копирование содержимого группы, то это может привести к появлению и быстрому размножению огромных массивов информации.
С другой стороны, можно каждый раз сохранять только изменения - тогда массовые операции над группами будут выполняться медленнее, поскольку каждый раз потребуется восстанавливать актуальное состояние группы.
Заметим, что присутствие группового типа данных не является необходимым в модели, поскольку группы объектов могут быть смоделированы многими способами, например, через организацию списков. Однако работать с ним значительно удобнее, чем явным образом перебирать наблюдения и объекты.
Таким образом, в качестве простых типов данных, определенных для значений параметров удобно рассматривать следующие:
число с размерностью или без нее перечислимый тип собственно объекты стандартные типы, в том числе текст, изображение, звук и т.д. запрос группа значений определенного типа
Тип значения параметра должен определять область (множество) допустимых значений параметра. Множество может быть задано интенсионально либо экстенсионально на основе множеств, соответствующих другим типам данных. В соответствии с этим возможны следующие определения типа значения параметра:
предикат - процедура, определяющая принадлежность значения параметра типу перечисление - список допустимых значений параметра
Предикат может определять принадлежность значения типу не только на основании самого значения. Допустимость того или иного значения может определяться контекстом данного параметра. Например, для женщин и мужчин отличаются интервалы допустимых значений тонуса сосудов головного мозга, содержания гемоглобина в крови в норме и т.п.
В списке допустимых могут присутствовать значения, диапазоны значений разных типов и предикаты. Например, допустимыми значениями для уровня холестерина в крови могут, наряду с действительными числами, быть перечислимые значения {очень низкий, низкий, средний, высокий, очень высокий}
Как уже говорилось, при описании параметра в типе наблюдения можно указать тип значения. В этом случае при проведении наблюдений будет осуществляться контроль типов.
Тип параметра может быть также задан глобально, при его описании в проекте.
Тогда контроль типов также осуществляется и, кроме того, тип параметра в описании типа наблюдения должен соответствовать глобально определенному.
При задании типа параметра кроме типа допустимых значений параметра могут указываться также другие характеристики.
При проведении наблюдения параметр может инициализироваться. Возможны следующие варианты:
Инициализация заданным значением Инициализация значением, которое этот параметр имеет в текущем состоянии
В первом варианте может быть задано значение или запрос, поставляющий это значение. Запрос исполняется до того, как параметрам присваиваются значения. При инициализации параметра может происходить обращение к какому-либо источнику данных, если эти данные поставляются в автоматическом режиме от устройств регистрации. Таким образом, с помощью инициализации источник может быть определен в типе параметра.
Для параметра могут быть заданы процедуры, которые исполняются при присвоении параметру какого-либо значения и при запросе значения параметра. Это позволяет вызвать побочный эффект при обращении к параметру, например, при задании даты рождения может автоматически устанавливаться значение параметра "Возраст", а при запросе параметра может быть организован учет обращений к нему. В типичном случае эти процедуры отсутствуют.
Обычно для данных, полученных в каком-либо наблюдении, существует период времени, в течение которого их можно считать верными. По истечении этого периода достоверность данных снижается. Например, дата рождения пациента действительна всегда, номер документа, удостоверяющего личность можно считать действительным на протяжении десятков лет, адрес и телефон - на протяжении лет, вес с большой вероятностью не изменяется в течение одного - двух месяцев. Артериальное давление может изменяться каждый день. Поэтому при описании параметра можно задавать его "срок хранения", т.е. время, после истечения которого требуется повторное наблюдение данного параметра. До этого момента параметр в текущем состоянии определяется данными, полученными в последнем наблюдении.
После него значение параметра в текущем состоянии становится неопределенным. Таким образом, истечение указанного в определении параметра периода эквивалентно проведению нового наблюдения, в котором этому параметру (и всем, вычисленным с его использованием) приписывается значение ^.
Параметр может быть объявлен как обязательный или необязательный в каком-либо типе наблюдения. Обязательным параметрам в наблюдении этого типа должно быть присвоено значение, отличное от ^. Если параметр объявлен как обязательный и вычисляется на основании других параметров, то все параметры, от которых он зависит, становятся обязательными. Если вычисляемый параметр объявлен как необязательный, то он вычисляется только в том случае, если определены параметры, от которых он зависит.
Таким образом, при описании параметра определяются следующие его свойства:
Тип значения Инициализация Процедура, определяющая действия при присвоении параметру какого-либо значения, исполняющаяся после проверки соответствия типа Стандартный формат или другая процедура получения изображения Обязательный / необязательный Права доступа Период, в течение которого данные действительны
Переносимость и интероперабельность информационных систем и международные стандарты
Сергей Кузнецов
Продукты,
которые сегодня принято называть информационными системами, появились много лет назад. В
основе первых информационных систем находились мэйнфреймы компании IBM, файловая
систем ОС/360, а впоследствии ранние СУБД типа IMS и IDMS. Эти системы прожили долгую и
полезную жизнь, многие из них до сих пор эксплуатируются. Но с другой стороны, полная
ориентация на аппаратные средства и программное обеспечение IBM породила серьезную
проблему "унаследованных систем" (legacy systems). Увы, производственный процесс
не позволяет прекратить или даже приостановить использование морально устаревших систем,
чтобы перевести их на новую технологию. Многие серьезные исследователи сегодня заняты
попытками решить эту проблему.
Серьезность проблемы унаследованных систем
очевидно показывает, что информационные системы и лежащие в их основе базы данных
являются слишком ответственными и дорогими продуктами, чтобы можно было позволить себе
их переделку при смене аппаратной платформы или даже системного программного
обеспечения (главным образом, операционной системы и СУБД). Для этого программный
продукт должен обладать свойствами легкой переносимости с одной аппаратно-программной
платформы на другую. (Это не означает, что при переносе не могут потребоваться какие-нибудь
изменения в исходных текстах; главное, чтобы такие изменения не означали переделки
системы.)
Другим естественным требованием к современным информационным
системам является способность наращивания их возможностей за счет использования
дополнительно разработанных (а еще лучше - уже существующих) программных компонентов.
Для этого требуется обеспечение свойства, называемого интероперабельностью. Под
этим понимается соблюдение определенных правил или привлечение дополнительных
программных средств, обеспечивающих возможность взаимодействия независимо
разработанных программных модулей, подсистем или даже функционально завершенных
программных систем.
Каким же образом можно одновременно удовлетворить оба эти
требования уже на стадии проектирования и разработки информационной системы? Ответом,
который я люблю и считаю правильным, является следующий: следуйте принципам
Открытых Систем. Другими словами, максимально строго придерживайтесь
международных или общепризнанных фактических стандартов во всех необходимых
областях.
Рассмотрим немного подробнее, какие стандарты следует иметь в виду при
разработке информационной системы сегодня. При использовании текущей технологии
информационная система пишется на некотором языке программирования, в нее встраиваются
операторы языка SQL и, наконец, включает какие-либо вызовы библиотечных функций
операционной системы.
Соответственно, прежде всего следует обращать внимание на
степень стандартизированности используемого языка программирования. На сегодняшний день
приняты международные стандарты языков Фортран, Паскаль, Ада, Си и, совсем недавно, Си++.
Понятно, что Фортран, даже в своем наиболее развитом виде Фортран-95, не является языком,
подходящим для программирования информационных систем. Паскаль - очень приятный язык,
но чтобы не испортить впечатление от его приятности, в стандарт не включены средства
раздельной компиляции. Конечно, в принципе можно оформить полный исходный текст в виде
одного текстового файла, но вряд ли это разумно и практично. Язык Ада, вообще говоря,
пригоден для любых целей. На нем можно писать и информационные системы (что, кстати и
делают американские и некоторые отечественные военные). Но что-то я не видел счастливых
прикладных программистов, использующих язык Ада. Уж больно он громоздкий... Наиболее
хороший стандарт, на мой взгляд, на сегодняшний день существует для языка Си. Опыт
нескольких лет, прошедших после принятия стандарта, показывает, что при грамотном
использовании стандарта Си ANSI/ISO проблемы переноса программ, связанные с
особенностями аппаратуры или компиляторов практически не возникают (если учитывать
имеющиеся в самом стандарте рекомендации по созданию переносимых программ).
Прошлым
летом был, наконец, принят стандарт Си++. Видимо, это означает (по крайней мере, я на это
надеюсь), что еще через несколько лет можно будет говорить о мобильном программировании
на Си++ в том же смысле, в котором можно говорить об этом сегодня по отношению к
Си.
Почему, имея в виду взаимодействия с базами данных, мы говорим про язык SQL и
что с ним происходит? Здесь все не очень просто. SQL с самого своего зарождения являлся
сложным языком со смешанной декларативно-процедурной семантикой, не идеальным
синтаксисом, а кроме того, всегда содержал ряд темных мест (объем этой заметки не позволяет
даже привести примеры). Тем не менее, судьба распорядилась так, что именно SQL (хотя были и
другие кандидаты) стал единственным практически используемым языком реляционных баз
данных. К настоящему времени имеется два принятых стандарта SQL- SQL/89 и SQL/92.
Стандарт SQL/89 очень слабый, многие важные аспекты в нем не определены или отданы на
определение в реализации. С другой стороны, большинство современных коммерческих
реляционных СУБД на самом деле соответствуют стандарту SQL/89. Стандарт SQL/92 является
существенно более продвинутым, но язык SQL/92 настолько сложен, что к настоящему времени
нет практически ни одной СУБД, в которой он был бы полностью реализован (как правило,
реализуется расширенное подмножество языка). Ситуация не из приятных. Но тем не менее,
внимательный анализ языка показывает, что имеется практическая возможность создания
достаточно переносимых программ с использованием SQL/89. Для это нужно максимально
локализовать те части программы, которые содержат не стандартизованные конструкции, и
стараться не использовать расширения языка, предлагаемые в конкретной
реализации.
Между прочим, аналогичная ситуация существует и в области
операционных систем. Существующий сегодня набор стандартов происходит от интерфейсов
операционной системы Unix (SVID, POSIX, XPG и т.д.). В большинстве современных
операционных систем эти стандарты поддерживаются, но, как правило, любая ОС содержит
множество дополнительных средств. Если стремиться к достижению переносимости
приложения, следует стараться ограничить себя минимально достаточным набором стандартных
средств. В случае, когда нестандартное решение некоторой операционной системы позволяет
существенно оптимизировать работу информационной системы, разумно предельно
локализовать те места программы, в которых это решение используется.
Конечно,
следовало бы поговорить и о системных или "полусистемных" (middleware)
средствах поддержки интероперабельности программных компонентов, начиная от средств
межпроцессных взаимодействий, проходя через механизм вызова удаленных процедур и
заканчивая (сегодня!) Common Object Request Broker Architecture (CORBA).
Завершим
эту небольшую заметку тем, что для создания переносимых интероперабельных
информационных систем необходимо иметь или придумать для себя то, что принято называть
профилем (а может быть, лучше профайлом?) стандартов, в окружении которых
разрабатывается система. Чем правильнее выбран профиль, тем более вероятно вашей системе
удастся прожить долгую и счастливую жизнь. А как хочется, чтобы наши творения жили долго и
счастливо...
Сергей Кузнецов - главный редактор журнала "Открытые
системы", консультант . С ним можно связаться по телефону: (095) 932-9212.
#4/96
Переосмысление традиционной архитектуры систем баз данных
Упомянутые в разделе 2 тенденции развития технологии дают пользователям возможность реализовывать все более и более крупные приложения систем баз данных. Это привело к появлению множества архитектур, основанных на разделяемой памяти, разделяемых дисках, неоднородной памяти (NUMA) и кластерах компьютеров без общих ресурсов (sharing-nothing). Современные системы баз данных наиболее успешны на системах без разделяемых ресурсов, поскольку такие системы обладают лучшими характеристиками масштабируемости. Кроме того, в компьютерных кластерах используются доступные на рынке компоненты, и поэтому они могут быть гораздо дешевле. При работе в большом кластере оптимизатор системы баз данных должен учитывать балансировку загрузки, доступность дискового пространства и ограничения на выполнимые планы и реплики. В этом контексте проявляются и многие причины переосмысления оптимизации в федеративных системах баз данных (раздел 2).
В добавление к этому типичная вычислительная система может иметь терабайт основной памяти. "Горячие" таблицы и большинство индексов будут постоянно располагаться в основной памяти. Для этого потребуется переосмыслить архитектуры хранения. Например, B-деревья не являются оптимальной индексной структурой для данных в основной памяти. Кроме того, могут оказаться неподходящими стратегии буферизации, восстановления и многопользовательского доступа коммерческих систем баз данных.
К тому же, хотя объемы дисковой памяти возрастают очень быстро, время доступа уменьшается относительно медленно. Следовательно, объем данных, которые могут быть переданы в основную память за среднее время доступа, растет очень быстро. С другой стороны, быстро растет стоимость подвода головок устройства магнитного диска в сравнении со стоимостью передачи одного байта данных. Поэтому требуются архитектуры хранения, в которых существенно более серьезное внимание уделялось бы оптимизации движения головок. Кроме того, в будущем могут оказаться неуместными архитектуры, "скрывающие наличие подвижных магнитных головок", такие как RAID 5.
Для большинства организаций требуется непрерывное функционирование систем. Для разработки программной системы, которая никогда не выходит из строя, требуются удаленные реплики и динамическая реконфигурация. Неясно, следует ли управлять удаленными репликами на уровне дисков с использованием идей RAID, или на уровне систем баз данных путем перемещения журнала системы баз данных и повторного выполнения журнализованных операций в удаленном узле.
Для новых приложений, включая обработку графических образов, полученных со спутников, и ведение цифровых телевизионных архивов, требуются очень большие базы данных, объем которых измеряется в петабайтах или экзабайтах. Такие приложения смогут стать возможными, когда дисковая память подешевеет настолько, что можно будет работать со всеми требуемыми данными в стандартной двухуровневой иерархии памяти. В добавок к этому, возможно, станут доступны новые устройства памяти третьего уровня, основанные на технике голографии. Итак, трехуровневая иерархия памяти вполне возможна. Обеспечение экзабайтной памяти в многозвенных архитектурах, включая репликацию и копирование, представляет значительную сложную задачу.
Наконец, возрастает популярность трехзвенных архитектур приложений (thick middleware). В этом мире имеется только одна программа (сервер баз данных), работающая на уровне сервера и только одна программа (сервер приложений), работающая в промежуточном звене. Обе они должны поддерживать тысячи подключений. Оптимизация систем баз данных (и операционных систем) для такой среды является серьезной задачей.
В заключение заметим, что фундаментальная архитектура систем баз данных существует почти 20 лет. Мы полагаем, что настало время переосмыслить базовые архитектурные предположения в свете появления среды, которая будет доступна в 2010-ом году.
ПО "двойного назначения"
Современные требования к ИС масштаба предприятия настолько многообразны и подчас противоречивы, что удовлетворение их в полном объеме практически невозможно. Однако, вполне понятно желание разработчиков удовлетворить максимально возможное количество требований потребителей. Речь в данном случае идет не только о технических и функциональных требованиях, но также и о финансовых, временных и даже эстетических. Именно поэтому в последнее время очень широкое распространение получили комплексные программные продукты, ориентированные на очень быстрое развертывание первой очереди ИС, реализующий базовый функционал, и последующую разработку приложений, повышающую степень автоматизации работ, выполняемых персоналом.
Подобным свойством "двойного назначения" обладает, по-видимому, вообще любое ПО из представленных на рынке: от офисных пакетов до сложнейших систем управления базами данных и онлайнового анализа информации. Таким образом, вообще все ПО можно разделить на три довольно неравных (по количеству представителей, их стоимости и распространенности на рынке) группы по степени выраженности его "двойного назначения".
В первую группу попадает ПО, на 90-95% ориентированное на использование базового функционала, но допускающее некоторое дополнение его самостоятельно создаваемыми возможностями. К этой категории относятся большинство широко используемых офисных наборов - текстовых процессоров, электронных таблиц, пакетов презентационной графики, персональных органайзеров и т.п. Так, например, текстовый процессор Microsoft Word содержит очень большое количество встроенных функций, которые, при необходимости, могут дополняться пользователем. Для этого предусмотрена возможность создания макропрограмм с применением языка Visual Basic и даже встроенной (являющейся неотъемлемой частью ПО Word) среды визуального программирования. Для подавляющего большинства пользователей уже встроенных функций достаточно (точнее говоря, из них используется не более 20-50%). И "допрограммирование" нового функционала является действительно опциональным: ПО полностью сохраняет свою ценность и без него.
Важно, что ПО первого типа в основном персональное, то есть не требующее (или даже не поддерживающее) сетевого взаимодействия.
Ко второй группе относится ПО, на 95-100% ориентированное на использование функционала, задаваемого (программируемого) пользователем или, чаще, третьей стороной - разработчиком, для конечного пользователя. К этой категории относится сложное и дорогое ПО: ERP, RDBMS, OLAP, Middleware, серверы приложений и т. д. Но, тем не менее, эти продукты сохраняют возможность (относительно) быстрого развертывания и использования стандартных шаблонов. Другое дело, что практическое применение их в такой конфигурации бессмысленно. Более того, бюджет подобных проектов всегда включает настройку базового ПО, создание заказных приложений в новой среде, обучение пользователей, поддержку и т. д. ПО этого типа практически всегда требует сетевого взаимодействия, то есть оно всегда многопользовательское.
ПО Lotus Domino/Notes относится к третьей группе. Domino можно успешно, без какого либо ущерба, использовать как в качестве ПО быстрого развертывания для создания системы электронной почты и календарного планирования, совмещенной с телеконференциями, общим каталогом пользователей и т. д., так и для разработки и внедрения достаточно сложной, комплексной заказной ИС для организации практически любого масштаба. Более того, не существует теоретических ограничений на использование Domino и Notes в обоих качествах одновременно в одной организации. Такая перспектива, безусловно, и явилась причиной значительного распространения Lotus Domino/Notes, ведь она обещает экономию материальных средств на ПО и оборудование, обслуживающий персонал, обучение пользователей и т. п., то есть снижение так называемой совокупной стоимости владения (Total Cost of Ownership - TCO).
Следует отметить тот факт, что в случае с истинным ПО "двойного назначения", невозможно оценить насколько встроенные или созданные пользователем функции превосходят друг друга. В подавляющем большинстве случаев соотношение между ними постоянно меняется вследствие постоянного стремления пользователя понизить TCO как раз за счет повторного использования установленных и сконфигурированных компонентов для реализации собственного функционала.
В третью группу также входит и ряд других программных продуктов других производителей. Это, например, Microsoft Exchange, или персональные СУБД, такиt как Microsoft Access или Lotus Approach, входящие в так называемые "профессиональные" версии офисных пакетов. Но все эти продукты скорее можно оценить, как имеющие соотношение от 30-70% до 70-30% между встроенными и программируемыми функциями. Причем этот процент не меняется или меняется очень незначительно в процессе эксплуатации ПО, что сильно отличает их от Lotus Domino/Notes. Но все соображения, которые изложены ниже и получены в результате работы с Domino и Notes, вполне относятся и другим продуктам третьей группы, хотя и в несколько меньшей степени. Все продукты этой группы поддерживают сетевое взаимодействие, многие имеют два варианта установки и работы - одно- и многопользовательские.
Почему мы нуждаемся в relvar?
Как отмечалось в аннотации, термин relvar является сокращением для термина реляционная переменная (relation variable). Он был введен нами с Хью Дарвеном в [9], первым опубликованном варианте Третьего Манифеста. Кодд в своих первых статьях о реляционной модели [3-4] использовал вместо него термин изменяемое во времени отношение (time-varying relation), но «изменяемые во времени отношения» – это те же relvar под другим именем. Конечно, мы не утверждаем, что были первыми, кто установил наличие этого факта, но мы полагаем, что были первым, уделившими ему серьезное внимание. Замечание: В публикации [2], появившейся на несколько лет ранее Третьего Манифеста, также проводится явное различие между отношениями и relvar (в ней они называются таблицами и табличными переменными соответственно). Однако это было сделано только под непосредственным влиянием моих комментариев, сделанных по поводу раннего варианта работы, в котором такое различие не проводилось.
Далее, мы полагаем, что понятие relvar и родственное понятие реляционного присваивания являются существенными, если нам требуется возможность обновления базы данных. Заметим, что переменные и присваивания действуют рука об руку (невозможно иметь одно без другого) – наличие переменной означает возможность присваивания этой переменной, а наличие возможности присваивания чему-либо означает, что это «что-либо» является переменной. Заметим также, что «возможность присваивания» («assignable to») и возможность обновления («updatable») означают ровно одно и то же; следовательно, возражения против relvar являются возражениями против реляционного обновления (эквивалентно, возражения против реляционного обновления являются возражениями против relvar).
По-видимому, здесь требуется небольшое дополнительное пояснение. Большая часть людей, говоря про реляционное обновление вообще, вероятно, имеет в виду традиционные операции INSERT, DELETE и UPDATE, а не реляционное присваивание – в особенности, в связи с тем, что, в частности, в SQL не поддерживается реляционное присваивание, хотя, конечно, поддерживаются INSERT, DELETE и UPDATE.
Но, в конечном счете, оказывается, что INSERT, DELETE и UPDATE являются всего лишь сокращенными формами некоторых видов реляционного присваивания. Например, предположим, что имеется обычная база данных поставщиков и деталей (примерный набор значений см. на рис. 1). Тогда оператор INSERT языка Tutorial D
INSERT SP RELATION
{ TUPLE { S# S#('S3'), P# P#('P1'), QTY QTY(150) },
TUPLE { S# S#('S5'), P# P#('P1'), QTY QTY(500) } } ;
является сокращенной формой оператора присваивания
SP := ( SP ) UNION ( RELATION
{ TUPLE { S# S#('S3'), P# P#('P1'), QTY QTY(150) },
TUPLE { S# S#('S5'), P# P#('P1'), QTY QTY(500) } } ) ;
Аналогично, оператор DELETE языка Tutorial D
DELETE S WHERE CITY = 'Athens' ;
является сокращенной формой оператора присваивания
S := S WHERE NOT ( CITY = 'Athens' ) ;

Рис. 1. База данных поставщиков и деталей – примерные значения
И оператор UPDATE языка Tutorial D
UPDATE P WHERE CITY = 'London'
( WEIGHT := 2 * WEIGHT, CITY := 'Oslo' ) ;
(немного более хитрым образом) является сокращенной формой оператора присваивания
P := WITH ( P WHERE CITY = 'London' ) AS T1,
( EXTEND T1
ADD ( 2 * WEIGHT AS NW, 'Oslo' AS NC ) ) AS T2,
( T2 { ALL BUT WEIGHT, CITY } ) AS T3,
( T3 RENAME ( NW AS WEIGHT, NC AS CITY ) ) AS T4,
( P MINUS T1 ) AS T5 :
T5 UNION T4 ;
Поэтому должно быть понятно, что реляционное присваивание, по существу, является единственной требуемой операцией реляционного обновления. По этой причине далее в этой статье я сфокусируюсь именно на реляционном присваивании. Кроме того, далее в статье я буду использовать (a) неуточненный термин присваивание в смысле реляционного присваивания и (b) неуточненный термин отношение в смысле значения отношения (за исключением, возможно, цитат из работ других авторов).
Почему мы стремимся к вычислительной полноте
Вот снова ОО-предписание 3 в своей исходной формулировке:
D должен быть вычислительно полным. Это значит, что в D может поддерживаться механизм вызовов из так называемых основных (host) программ, написанных на языках, отличных от D (но эта поддержка не является обязательной). Аналогично, в D может поддерживаться использование других языков для реализации операций, определяемых пользователями (но эта поддержка не является обязательной).
В [1] это предписание комментируется следующим образом:
Я не понимаю текст, начинающийся с «Это значит», – он не является определением того, что означает вычислительная полнота языка. Наличие программ, написанных на других языках, которые можно вызывать из конструкций данного языка или из которых можно вызвать программы, написанные на данном языке, не делает этот язык вычислительно полным.
Конечно, я согласен с тем, что текст, начинающийся с «Это значит», не является определением вычислительной полноты; он для этого и не предназначался, и может быть желательна некоторая переформулировка. Скорее, этот текст предназначался для разъяснения некоторых последствий вычислительной полноты языка D – другими словами, он предназначался для разъяснения того, почему мы считаем вычислительную полноту хорошей идеей. В своей части [1] Хью писал следующее:
Я надеюсь, что обоснование нашего включения требования вычислительной полноты является очевидным. Частично оно состоит в том, что тогда приложения могут писаться на языке D, что позволяет избежать проблем, связанных с потребностью писать их на другом языке, а частично в том, что обеспечивается возможность использования языка D для кодирования реализаций операций, определяемых пользователями.
В ходе дальнейшей переписки в ответ на уже обсуждавшиеся мной критические замечания Хью сказал следующее:
Возможно, нам следовало сказать что-нибудь, подобное следующему: Язык D должен включать полный набор возможностей для реализации приложений баз данных и операций, определяемых пользователями. Для достижения целей было бы достаточно наличия вычислительно полного языка, но от D не требуется вычислительная полнота; не требуется и наличие возможности написания на языке D приложений и операций, определяемых пользователями.
Но если мы соглашается отступить от вычислительной полноты, то как далеко мы можешь отойти? – т.е. где мы проведем границу? Насколько много вычислительных действий можем мы поддерживать безопасно? Если верно то, что вычислительная полнота означает всего лишь возможность вычислять все вычислимые функции, а вычислимая функция означает всего лишь функцию, которую можно закодировать с использованием циклов WHILE, то следует ли нам запретить циклы WHILE? Если да, то с чем мы останемся? Замечание: Конечно, эти вопросы являются теоретическими. Моя позиция достаточно очевидна: я не думаю, что мы можем отойти от вычислительной полноты. Более того, Хью согласен со мной; его намек на то, что от D может не требоваться вычислительная полнота, не был серьезным.
Но имеется еще одна проблема, которую я должен затронуть при обсуждении нашего стремления к вычислительной полноте языка D. Среди прочего, вычислительная полнота означает возможность включения в реляционные выражения вызовов определяемых пользователями операций только чтения, возвращающих значения-отношения, – операций, реализация которых может быть закодирована на самом языке D, возможно, с использованием циклов и других процедурных конструкций, – и некоторые критики могут счесть эту возможность противоречащей исходной цели Кодда относительно того, что все запросы и пр. должны представляться декларативно. Однако мы утверждаем, что вызовы операций только чтения являются в равной степени декларативными, независимо от того, где, как, кем и на каком языке эти операции реализованы (и независимо от того, являются ли они возвращающими значения-отношения). Для иллюстрации рассмотрим следующий пример:
OPERATOR TABLE_NUM ( K INTEGER )
RETURNS RELATION { N INTEGER } ;
... implementation code ...
END OPERATOR ;
При вызове эта операция возвращает отношение, представляющее предикат «N является целым числом в диапазоне от 1 до K» (полезность такой операции демонстрируется в [6]). Тогда, конечно, вызов, например, TABLE_NUM (3149) является в равной степени «декларативным» вне зависимости от того, (a) написан ли код реализации на языке D тем же пользователем, который производит вызов, или (b) он написан некоторым другим пользователем на некотором другом языке, или (c) он предоставляется в составе СУБД.
Поддержка Active Accessibility
Много людей с проблемами зрения, слуха или моторики не могут использовать приложения запускаемые в MS Windows без помощи Accessibility Aids.Microsoft Active Accessibility предоставляет встроенные в Windows компоненты на основе технологии COM. Эта технология определяет, как приложение должно изменить пользовательский интерфейс, чтобы люди с ограниченными возможностями смогли получить доступ к работе с программой.
Подходы к реализации
В разделе статьи были выделены две основные проблемы, присущие языку XQuery при выражении логики работы с модифицированным состоянием XML-данных. С точки зрения программиста на языке Xquery, - это громоздкость и невыразительность выражений XQuery, описывающих требуемую логику обработки данных. С точки зрения разработчика Xquery-процессора, - это вопрос эффективного выполнения таких запросов.
Во разделе были продемонстрированы компактность и выразительность запросов, записанных на варианте языке XQuery, который расширен предложенными функциональными update-выражениями. Для практического применения необходим способ эффективного вычисления функциональных update-выражений, пригодный для работы с большими объемами XML-данных. При вычислении выражений неприемлемо сканирование данных целиком для выполнения, например, замены одного элемента другим. Необходимо гарантировать произвольный доступ к данным (random-access). Далее будут рассматриваться возможные подходы к реализации, удовлетворяющие условию произвольного доступа к данным.
При введении функциональных update-выражений в язык XQuery обсуждалась доступность в одном XQuery-выражении исходного и модифицированного состояний данных. Предлагаемые ниже подходы к реализации вносят некоторые ограничения на это свойство функциональных update-выражений, о чем будет говориться более детально в каждом конкретном случае.
Подставляемость и преобразование объектных типов в иерархии
Стивен Фернстайн
(Substituting and Converting Object Types in a Hierarchy, by Steven Feuerstein)
Источник:
В этой статье Стивен Фернстайн рассматривает преимущества и гибкость иерархий объектных типов, исследуя подставляемость и преобразование типов.
В одном из препдыдущих выпусков Oracle Professional я рассматривал одно из наиболее важных расширений языка SQL и PL/SQL: поддержку наследования объектных типов. При наследовании подтип наследует все атрибуты и методы своих супертипов - причем наследует их не только непосредственно этот подтип, но и любой подтип или потомок в результирующей иерархии объектного типа. Наследование позволяет реализовать бизнес логику на нижних уровнях иерархии и затем сделать ее автоматически доступной во всех объектных типах, выводимых из этих супертипов. Вам не придется кодировать бизнес-правила много раз, чтобы использовать их в различных объектных типах в иерархии.
Наследование также позволяет разработчикам использовать преимущество "динамического полиморфизма", это означает, что во время запуска программы, Oracle находит и выполняет "ближайший" или наиболее характерный метод в объектной иерархии, который соответствует вызову данного метода.
Подзапрос
Наконец, последняя конструкция SQL/89, которая может содержать табличные выражения, - это подзапрос, т.е. запрос, который может входить в предикат условия выборки оператора SQL. В SQL/89 к подзапросам применяется то ограничение, что результирующая таблица должна содержать в точности один столбец. Поэтому в синтаксических правилах, определяющих подзапрос, вместо списка выборки указано "выражение, вычисляющее значение", т.е. арифметическое выражение. Заметим еще, что поскольку подзапрос всегда вложен в некоторый другой оператор SQL, то вместо констант в арифметическом выражении выборки и логических выражениях разделов WHERE и HAVING можно использовать значения столбцов текущих строк таблиц, участвующих в (под)запросах более внешнего уровня. Более подробно мы обсудим это ниже при описании семантики табличных выражений.
Поиск
В операции поиска требуется указать следующую информацию:
что требуется найти - объект или наблюдение используется ли полное состояние или только наблюдения указанного типа интервал времени, за который рассматриваются состояния или текущее состояние условие поиска
Если интервал времени не указывается, то считается, что рассматривается текущее состояние объекта. Если же интервал задается, то в условии требуется дополнительно уточнить, когда оно выполняется. Возможны следующие варианты:
условие выполняется во всех состояниях на указанном интервале времени условие выполняется хотя бы в одном состоянии условие не выполняется ни в одном состоянии
Таким образом, каждое логическое выражение в условии поиска может быть предварено указанием на количество наблюдений на данном интервале, удовлетворяющих этому условию ("временной квантор").
Возможны более сложные условия поиска. Если A и B - логические выражения, то можно задавать причинно-следственные связи, например, "Если A, то B до или после A"
Помимо этого, возможно указывать временной интервал непосредственно вместе с каждым простым условием: (A в интервале T1) И (B в интервале T2).
В качестве примера рассмотрим, как мог бы выглядеть запрос на гипотетическом языке манипулирования данными для рассматриваемой модели.
select object о using observations of type General_Info, Visit_To_Phisician on time interval [01.01.2000..01.01.2001] where (о.age > 35 (year)) and (о.age<72 (year)) and (о.gender = femal) and never ( о.systolic_blood_pressure > 130 (mm Hg)) // эквивалентно always not (<condition>) and at least once ( о.wheight / (о.height*о.height) > 30 (Kg/m^2))
Приведенная запись соответствует запросу "Найти всех женщин в возрасте на момент обследования от 35 до 72 лет, обследованных за 2000 год, у которых систолическое артериальное давление за этот период никогда не превышало 130 мм рт.ст. и хотя бы один раз зафиксирован избыточный вес (индекс массы тела >30)"
Предполагается, что в проекте описаны типы наблюдения General_Info, в котором регистрируется параметр gender - пол пациента, и Visit_To_Phisician, где фиксируются остальные параметры, участвующие в приведенном запросе. Фраза using указывает на то, что условие будет проверяться только для тех объектов, для которых проведено хотя бы по одному наблюдению этих типов. В данном примере также следует обратить внимание, что за значениями в скобках указывается последовательность символов, определяющая размерность значения - при написании запроса пользователю достаточно знать только размерность и нет необходимости помнить в каких именно единицах измеряется данный параметр.
Условия поиска с учетом временных связей между событиями заслуживают более пристального внимания. В частности можно рассмотреть возможность использования диалекта SQL/Temporal или построения специфического языка запросов на основе темпоральной логики [4]. Однако детальная разработка языка не входит в число задач данной работы.
Поисковый механизм
После того как мы проиндексировали наши документы, нужно понять какие запросы посылать в базу, что бы искать эти документы по ключевым словам. Предположим, есть поисковая фраза "река объ". Пользователю необходимо получить все документы содержащие эти два слова. Сначала нужно обратиться к таблице dictionary и узнать уникальные id этих слов, далее будем их называть $dict_id1 и $dict_id2. Потом необходимо послать такой запрос в таблицу match, который выдаст только те номера документов, которые содержат эти два слова. Вот пример этого запроса: SELECT doc_id FROM match where dict_id =$dict_id1 group by doc_id INTERSECT SELECT doc_id FROM match where dict_id=$dict_id2 group by doc_id. В случае если пользователь введет три слова, то вам придется добавить еще раз INTERSECT и третью часть SQL запроса. По полученным в результате запроса doc_id можно извлечь информацию об имени файла документа из таблицы document.
Пользователи и права доступа
Очевидно, с системой могут работать одновременно много пользователей. В этом случае должно существовать разграничение прав доступа этих пользователей к объектам и результатам проведенных наблюдений. В случае возникновения противоречия в значениях параметров, касающихся одного объекта, эти противоречивые точки зрения на объект должны отражаться в системе. Соответствующие состояния объекта должны быть равноправны.
Предположим, в системе зарегистрированы два пользователя - u' и u'', которые производят повторное наблюдение объекта o, находящегося в состоянии s1 (рис.4). После проведения этих наблюдений для пользователя u' объект виден в состоянии s2', а для пользователя u'' - в состоянии s2''. Если один из пользователей - u'- дает право доступа к своим наблюдениям пользователю u'', то u'' при повторном наблюдении видит два равноправных актуальных состояния объекта. Он может использовать одно из них в качестве исходного для повторного наблюдения - в этом случае он и далее будет видеть два состояния объекта - либо свести два этих состояния в одно, например, усреднив значения различающихся параметров или выбрав подходящие значения параметров из каждого состояния. Если новое наблюдение не затрагивает параметров, различающихся в расщепленном состоянии, то в этом случае такие параметры неразличимы и расщепление состояния сохраняется. На рисунке кружки обозначают состояния, стрелка - переход из одного состояния в другое.

Рис.4.
Как уже говорилось, расщепление состояний может возникать не только при передаче прав доступа, но и более простым способом - при проведении повторных наблюдений над объектом, когда в качестве исходного состояния принимается не текущее состояние, а одно из более ранних. Один из примеров такой ситуации - анализ "что если", когда одному параметру может быть приписано несколько вариантов значений в качестве гипотез и требуется найти оптимальный из этих вариантов.
Естественным представляется желание построить систему управления правами доступа с использованием тех же принципов и механизмов, которые используются для управления остальными данными.
Проблема прав доступа достаточно хорошо разработана в теории СУБД. Сложностью в предлагаемом подходе является то, что доступно не только текущее состояние объектов, но и их история. Таким образом, необходимо управлять правами доступа во времени, а не только в пространстве. В идеале пользователь даже не должен знать, что его права доступа к объекту ограничены или были ограничены.
Регистрация прав может осуществляться с использованием описанных механизмов. При этом имеет смысл предусмотреть для каждого субъекта общий режим, когда права описываются на уровне ролей, параметров и типов наблюдений и специальный режим, когда могут устанавливаться права исполнения любой операции для каждого пользователя и для каждого состояния.
В общем случае права доступа определяются следующими аспектами:
Тип -предоставление права или ограничение Операция, с помощью которой осуществляется доступ к данным Данные - объект, наблюдение (тип и экземпляр), параметр Кто является владельцем прав - конкретный пользователь или роль, в том числе предопределенные роли "пользователь" и "администратор" Интервал времени, на котором действует данное право - всегда, начиная с какого-либо момента или на временном отрезке.
Постреляционная СУБД Cache'
В.А. Федоров, консультант по продуктам, .
В конце 1997 года компания выпустила постреляционную СУБД Cache'. Компания и раньше занималась системами управления базами данных, в России активно использовались и продолжают использоваться предшественники Cache': MSM, DTM, ISM. За 4 года вышло несколько версий СУБД Cache', в настоящий момент компания предлагает Cache' 4.1.
Cache' 4.1. - высокопроизводительная промышленная СУБД, интегрированная с технологией разработки Web-приложений - Cache' Server Pages.
СУБД Cache' относится к постреляционным СУБД. Термин "постреляционная СУБД" обозначает принадлежность Cache' к СУБД нового поколения. Имеется в виду не столько аспект времени (Cache' появилась после своих основных реляционных конкурентов), сколько ряд технологических преимуществ: единая архитектура данных и полная поддержка Cache' объектно-ориентированных технологий, о которых будет подробно рассказано ниже.
На рисунке 1 изображены основные элементы архитектуры СУБД Cache': платформы, на которых работает Cache', Многомерный сервер данных, три способа доступа к данным, язык описания бизнес-логики Cache' ObjectScript, интерфейсы к средствам проектирования и разработки приложений и Web-технология Cache' Server Pages. Далее мы подробно остановимся на всех основных элементах архитектуры, которые будут рассмотрены подробнее.

Рисунок 1. Архитектура постреляционной СУБД Cache.
Cache' - кроссплатформенная система. Cache' поддерживает следующие операционные системы: всю линейку Windows, Linux, основные реализации Unix и Open VMS. Планируется поддержка новых реализаций Unix. Большое внимание уделяется новой платформе Itanium.
Данные в Cache' хранятся под управлением Многомерного сервера данных. В основе Cache' лежит транзакционная многомерная модель данных (TMDM), которая позволяет хранить и представлять данные так, как они чаще всего используются. Многомерный сервер данных снимает многие ограничения, накладываемые реляционными СУБД, которые хранят данные в двумерных таблицах, ведь если реляционная модель состоит из большого количества таблиц, что необходимо при работе со сложными структурами данных, это существенно усложняет и замедляет выполнение сложных транзакций и ведет к хранению излишней информации.
Cache' хранит данные в виде многомерных разреженных массивов - глобалей. Уникальная транзакционная многомерная модель данных позволяет избежать проблем, присущих реляционным СУБД, оптимизируя данные на уровне хранения.
В отличие от ранних многомерных СУБД, которые были оптимизированы для создания аналитических систем, Cache' ориентирована на системы обработки транзакций (Online Transaction Processing). Многомерный сервер данных Cache' предназначен для обработки транзакций в системах с большими и сверхбольшими БД (сотни гигабайт, терабайты) и большим количеством одновременно работающих пользователей. Многомерный сервер данных Cache' позволяет разработчикам получить великолепную производительность, отказавшись от хранения избыточных данных и таблиц. Реляционная модель не всегда подходит для описания сложных предметных областей. Транзакционная модель данных Cache' позволяет оптимизировать данные на уровне хранения, поддерживать объектную модель и сложные типы данных. Все эти возможности значительно упрощают создание сложных систем.
В Cache' реализована концепция Единой архитектуры данных. К одним и тем же данным, хранящимся под управлением Многомерного Сервера Данных Cache' есть три способа доступа: прямой, объектный и реляционный:

Рисунок 2. Концепция Единой архитектуры данных Cache'.
Cache' Direct Access - прямой доступ к данным, обеспечивает максимальную производительность и полный контроль со стороны программиста. Разработчики приложений получают возможность работать напрямую со структурами хранения. Использование этого типа доступа накладывает определенные требования на квалификацию разработчиков, но понимание структуры хранения данных в Cache' позволяет оптимизировать хранение данных приложения и создавать сверхбыстрые алгоритмы обработки данных. Cache' SQL - реляционный доступ, обеспечивающий максимальную производительность реляционных приложений с использованием встроенного SQL. Cache' SQL соответствует стандарту SQL 92. Кроме этого, разработчик может использовать разные типы триггеров и хранимых процедур.
Все это позволяет Cache' успешно конкурировать с реляционными СУБД. Даже без использования прямого и объектного доступа приложения на Cache' работают быстрее за счет высокой производительности Многомерного Сервера Данных. Cache' Objects - объектный доступ, для максимальной продуктивности разработки при использовании Java, Visual C++, VB и других ActiveX-совместимых средств разработки, таких как PowerBuilder и Delphi. В Cache' реализована объектная модель в соответствии с рекомендациями ODMG (Группа управления объектными базами данных - Object Database Management Group). В Cache' полностью поддерживаются наследование (в том числе и множественное), инкапсуляция и полиморфизм. При создании информационной системы разработчик получает возможность использовать объектно-ориентированный подход к разработке, моделируя предметную область в виде совокупности классов объектов, в которых хранятся данные (свойства классов) и поведение классов (методы классов). Cache', поддерживая объектную модель данных, позволяет естественным образом использовать объектно-ориентированный подход как при проектировании (в Rational Rose) предметной области, так и при реализации приложений в ОО-средствах разработки (Java, C++, Delphi, VB). Постреляционная СУБД Cache' конкурирует с объектными СУБД, значительно превосходя их по таким показателям как надежность, производительность и удобство разработки.
Как уже отмечалось, разработчик имеет три способа доступа к одним и тем же данным. Как только определяется класс объектов, Cache' автоматически генерирует реляционное описание этих данных так, что к ним можно обращаться, используя SQL. Подобным же образом, при импорте в словарь данных DDL-описания реляционной базы данных, Cache' автоматически генерирует реляционное и объектное описание данных, открывая тем самым доступ к данным как к объектам. При этом все описания данных ведутся согласованно, все операции по редактированию проводятся только над одним экземпляром данных. Кроме этого программист может обратиться к тем же данным с помощью прямого доступа.
Cache' позволяет комбинировать три типа доступа, оставляя разработчику свободу выбора. Например, при реализации биллинговой системы объектный доступ может использоваться при описании бизнес-логики приложения и создания пользовательского интерфейса с помощью объектно-ориентированных средств разработки (VB, Delphi, C++), реляционный доступ - для совместимости с другими системами и интеграции с инструментами построения отчетов и аналитической обработки данных (Seagate Info, Cognos, Business Objects). Прямой доступ обеспечивает максимальную производительность и может быть использован для реализации таких операций, в которых применение обычных хранимых процедур, основанных на SQL, не может обеспечить необходимую производительность. В биллинге к таким операциям относятся закрытие периода, массовая загрузка данных (CDR). Использование прямого доступа для реализации подобных операций позволяет увеличить производительность на 1-2 порядка.
Известны случаи перевода в Cache' сложных приложений, которые ранее работали под управлением реляционных СУБД. Например, один из партнеров InterSystems перевел на Cache' биллинговую систему для операторов сотовой связи. Переход осуществлялся следующим образом: сначала существующее приложение с минимальными изменениями переносится под управление Cache'. Приложение на первом этапе работает с Cache', так же как и с реляционной СУБД. Опыт показывает, что даже в этом случае, система начинает работать быстрее. Далее ряд операций был переписан, с использованием прямого способа доступа к БД. На этом этапе удалось увеличить производительность критических операций в десятки и сотни раз.
Кроме этого, можно провести реинжениринг системы. Существует возможность значительно увеличить производительность системы, используя полную поддержку Cache' объектно-ориентированных технологий. При этом можно изменять и структуру базы, и способ работы с Cache' из клиентской части приложения.
Для реализации бизнес-логики БД в СУБД Cache' используется Cache' Object Script.
COS - полнофункциональный язык, который имеет все необходимые механизмы для работы с данными с помощью любого способа доступа. С помощью COS разработчик создает методы классов, триггеры, хранимые процедуры, различные служебные программы. В настоящее время ведется работа над созданием еще одного языка описания бизнес-логики - Бейсика. Использование Бейсика позволит облегчить изучение Cache' большому количеству программистов, владеющих этим широко распространенным языком.
СУБД Cache' - открытый продукт, который имеет множество интерфейсов, позволяющих разработчику использовать вместе с Cache' любые современные технологии.
Во-первых, стоит отметить интерфейсы со средствами проектирования и разработки приложений. Специальные компоненты Cache' позволяют проектировать приложения в Rational Rose при объектном подходе, и в ErWin - при реляционном.
Разработчик может реализовывать приложения клиент-сервер, используя практически все средства разработки. При этом он может использовать специальные интерфейсы для прямого и объектного доступа, а стандартные (ODBC, JDBC) - для реляционного. Особый интерес представляет работа с помощью объектного способа доступа в объектно-ориентированных средствах разработки: разработчик работает с классами объектов Cache', обращаясь к их свойствам и выполняя методы классов, так же как и с собственными объектами языка программирования.
Кроме этого, поддерживаются следующие интерфейсы: Native C++, Java, EJB, ActiveX, XML, интерфейсы CallIn и CallOut .
О XML стоит рассказать подробнее. Сейчас уже нет необходимости доказывать преимущества применения XML. Такие задачи как обмен информацией между различными информационными системами, новые протоколы роуминга (например, TAP3), разработка приложений мобильной коммерции решаются с помощью XML. Следовательно, современная СУБД должна предоставлять необходимые механизмы работы с XML.
В Cache' реализована полноценная поддержка XML. Cache' не хранит XML-документы в текстовых файлах, Memo-полях или реляционных таблицах.
Полная поддержка Cache' объектной модели позволяет автоматически трансформировать сложные XML-документы в классы объектов Cache'. Из описания классов объектов Cache' можно получить DTD, а сами объекты Cache проецируются в XML-документы. Для создания собственного импорта XML можно воспользоваться SAX-парсером. С помощью Cache' Server Pages, Web-технологии компании InterSystems, можно генерировать не только HTML страницы, но и страницы с XML-содержанием.
Таким образом, появляется возможность использовать XML с Cache' как для обмена информацией между различными информационными системами, так и для реализаций приложений электронной и мобильной коммерции (WAP).
Хотелось бы также подробнее остановится на возможностях разработки Web-приложений в Cache'. Cache' Server Pages - объектная Web-технология Cache', позволяющая использовать производительность и масштабируемость СУБД Cache' для быстрого создания сложных Intranet- и Internet-приложений, взаимодействующих с БД. При разработке Web-приложений, Cache' является не только СУБД, но и Сервером Приложений. В Cache' хранятся классы, соответствующие CSP-страницам, и при обращении к CSP-странице выполняются методы, генерирующие HTML или XML. Технология Cache' Server Pages - обеспечивает обмен данными между постреляционной СУБД Cache' и Web-сервером, используя стандартные интерфейсы. Такая архитектура позволяет создавать высокопроизводительные, масштабируемые Internet- или Intranet-приложения, так как, во-первых, данные хранятся очень близко к Web-приложению (данные из БД передаются в приложение через высокопроизводительные внутренние интерфейсы, а не через ODBC или JDBC), и, во-вторых, относительно небольшая нагрузка на Web-сервер (Web-сервер только перенаправляет запросы пользователей на Сервер приложений Cache') и высокая производительность СУБД Cache' позволяет обрабатывать запросы большого количества пользователей.
Процесс разработки выглядит следующим образом, дизайнеры занимаются внешним видом Web-приложения, а разработчики с помощью готовых инструментов разработки Web-страниц (например, Macromedia Dreamweaver) или любого текстового редактора дополняют Web-страницы необходимой функциональностью.
Для разработки CSP- страниц используются стандартные таги HTML, а также набор дополнительных CSP-тагов и атрибутов для реализации циклов, условий, связывания объектов Cache и формы CSP-страницы, управления данными и т.д. Существует возможность разрабатывать собственные таги приложений (Cache' Application Tags). Cache Server Pages позволяет разработчику использовать для создания методов Cache Object Script, Java и VB script. Механизмы наследования CSP-страниц (CSP - объектно-ориентированная технология, где все CSP-страницы - классы) и собственные таги Cache' обеспечивают возможность повторного использования кода и совместной разработки: например, часть разработчиков будут создавать таги приложений, а другие - использовать созданные таги для конструирования сложных Web-приложений. Такие возможности как поддержка сессии, Гипер-события (изменение содержимого Web-страницы без её перезагрузки), собственные таги позволяют быстро разрабатывать Web-приложения, которые по функциональности ничем не уступают традиционным приложениям "клиент-сервер".
Партнеры InterSystems используют CSP для написания приложений самой разной сложности. На CSP реализованы различные информационные системы, электронные магазины, системы электронного документооборота, системы для расчета с населением по оплате коммунальных услуг и ряд других интересных приложений.
Разработчики крупных приложений (банковские системы, автоматизированные системы расчетов, системы управления предприятием) предпочитают использовать промышленные СУБД. Cache' обладает всеми характеристиками промышленной системы: высокой производительностью, надежностью, масштабируемостью, открытостью и переносимостью. Ядро Cache' - высокопроизводительный Многомерный сервер данных, ориентированный на обработку транзакций. Для обеспечения надежности в Cache' предусмотрены такие механизмы как журнал до и после записи, теневой сервер, репликация, "горячее" резервное копирование и т.д. Протокол Распределенного Кэша - позволяет строить действительно масштабируемые решения на базе Cache'.
Протокол Распределенного Кэша (Cache' Distibuted Cache' Protocol) - уникальная сетевая технологи фирмы InterSystems, которая распределяет базу данных по сети в зависимости от работы приложений, оптимизируя производительность и пропускную способность сети. Cache' - "открытая" система, поддерживается множество интерфейсов к средствам проектирования и разработки приложений. Cache' работает практически на всех популярных платформах с наиболее распространенными Web-серверами. При этом обеспечивается полная переносимость приложений с платформы на платформу.
Еще один важный показатель как для производителя, так и для потребителя системы на базе СУБД - стоимость решения. Этот показатель складывается из стоимости разработанной системы, стоимости аппаратного обеспечения, на котором будет работать система, СУБД, стоимости внедрения и сопровождения. Решения на базе постреляционной СУБД Cache' выигрывают по стоимости у конкурентов по всем показателям. Разработчик может быстро и качественно создать систему на базе Cache' за счет поддержки объектно-ориентированного подхода и интеграции со средствами проектирования и разработки, СУБД менее требовательна к аппаратному обеспечению: нужной производительности можно добиться на более дешевом сервере, гибкая лицензионная политика позволит снизить стоимость самой СУБД. Решения на базе СУБД легче сопровождать - система очень надежна и не требует сложного администрирования, кроме этого прекрасно работают и мировой, и российский центр технической поддержки.
Один из партнеров InterSystems - разработчик АСР для операторов сотовой связи выиграл тендер у конкурентов, которые предлагали решение на Oracle, после того как был выполнен пилотный проект. В этом проекте в Cache' и Oracle были загружены данные о звонках, и измерялась скорость закрытия периода для загруженных тестовых данных. Хранимая процедура на Cache' работала 40 минут, на Oracle - 2 часа. При этом Cache' работала на сервере стоимостью 5 тысяч $, а Oracle на сервере Sun за 50 тысяч $.
Таким образом, решения на базе Cache' позволяют разработчикам ПО получить дополнительную прибыль от разработки, а потребителям - получить высокопроизводительные решения, сэкономив на приобретении и эксплуатации приложения.
СУБД Cache' становится все более популярной России. На продуктах реализованы банковские системы, автоматизированные системы расчетов для предприятий электросвязи и операторов сотовой связи, системы управления предприятиями, тарификационные системы, Web-порталы и другие интересные приложения. Сегодня есть все предпосылки для роста популярности постреляционной СУБД Cache' в России: промышленная СУБД, поддерживающая объектную модель, предоставляющая разработчику свободу в выборе средств проектирования и разработки, интегрированная с технологией разработки Web-приложений, позволяет быстро создавать надежные высокопроизводительные решения.
Практические соображения
В процессе реализации LEO требовалось также учитывать некоторые практические соображения.
Клятва Гиппократа: «Не навреди!» Основная цель самонастраивающегося оптимизатора состоит в улучшении производительности запросов за счет настройки существующей модели на основе ранее выполненных запросов. В идеале эта настроенная модель обеспечивает улучшенный базис для принятия решений при выборе наилучшего плана выполнения запроса. Однако эти обретенные знания должны использоваться исключительно консервативно: не следует делать поспешные выводы, опираясь на неубедительные или отрывочные данные. В критических приложениях стабильность и надежность обработки запросов часто более приоритетны, чем оптимальность со случайным и непредсказуемым поведением. Если немедленно принимать во внимание поправки при оптимизации запросов, то в условиях весьма динамичной базы данных для одного и того же запроса могут генерироваться разные планы выполнения при каждом поступлении запроса, а это может привести к «пробуксовке» планов выполнения. Такой нестабильности можно избежать, если инициировать повторную оптимизацию запросов после того, как получаемые знания сошлись к фиксированной точке или достигли определенного порога надежности.
Согласованность статистики. В DB2 статистические показатели собираются для базовых таблиц, столбцов, индексов, функций и полей, и многие показатели являются взаимозависимыми. Пользователям DB2 дается возможность обновлять статистику в каталогах и выполнять при таких обновлениях проверку несогласованности. Самонастраивающийся оптимизатор должен аналогичным образом обеспечивать согласованность этих взаимозависимых статистик при корректировке любой из них. Скажем, число строк в таблице определяет число дисковых страниц, используемых для хранения этих строк. Поэтому при корректировке числа строк в таблице необходимо обеспечить согласованность с числом страниц для этой таблицы (например, изменив и этот параметр), иначе выбор плана может оказаться зависимым от вида используемой статистики.
Необходимо сохранять и согласованность между индексными и табличными статистическими показателями, поскольку могут существовать взаимозависимости между числом различных значений столбца и числом строк в таблице. Однако увеличение числа строк не всегда приводит к увеличению числа различных значений. Хотя при последовательной вставке строк число различных значений в столбце date (дата) изменится, это маловероятно для такого столбца, как sex (пол), для которого предполагается наличие только значений male (мужской) или female (женский), вне зависимости от числа строк.
Корректирование или статистика базы данных. Самонастраивающийся оптимизатор не заменяет собой статистические показатели базы данных, а дополняет их. Статистика собирается в базе данных единообразно в расчете на обработку любого возможного запроса. Обратная связь наиболее значительно позволяет улучшить моделирование запросов, которые либо повторяются, либо аналогичны ранее выполненным запросам, т. е. запросов, для которых в модели оптимизатора используется одна и та же статистическая информация. Обратная связь расширяет возможности утилиты RUNSTATS за счет сбора информации о производных таблицах (например, о результате нескольких соединений) и накапливает более детальную информацию, чем это может сделать RUNSTATS. Со временем оценки оптимизатора будут улучшены в большинстве областей базы данных, к которым обращается большинство запросов. Однако для корректной оценки стоимости ранее не выполнявшихся запросов статистика, собранная RUNSTATS, необходима даже при наличии обратной связи запросов.
Практические задачи
Чтобы на конкретных примерах проиллюстрировать, о чем пойдет речь, рассмотрим несколько задач, связанных с наблюдением над объектами реального мира.
1. Медицина и медико-биологические исследования. Врачи осуществляют наблюдения за пациентами. Каждый прием у специалиста сопровождается фиксацией некоторых параметров пациента: фамилия, имя, отчество, страховой полис и/или номер амбулаторной карты больного, рост, вес, пульс, возраст, ЧСС, артериальное давление, жалобы, симптомы и прочее. Кроме того, возможно проведение анализов и инструментальных обследований, при которых фиксируются количественные и качественные параметры. Ряд параметров не изменяется или изменяется крайне редко - это такие параметры как фамилия, пол, адрес пациента, рост для взрослых пациентов. Такие параметры достаточно зафиксировать один раз при первичном приеме Другие параметры (артериальное давление, температура тела) изменяются от одного обследования к другому довольно сильно и требуют постоянного мониторинга. Некоторые параметры могут фиксироваться от случая к случаю, другие фиксируются регулярно. На основании данных обследований могут назначаться те или иные дополнительные обследования. Требуется организовать информацию таким образом, чтобы позволить с минимальными затратами проводить первичные и повторные приемы, т.е. свести к минимуму набор вводимой каждым специалистом информации и исключить повторный ее ввод, обеспечить совместный доступ к информации с ограничением прав доступа для конкретных пользователей, проводить оценку эффективности лечения, обеспечить возможность планирования обследований и лечения, выделение групп риска по различным заболеваниям, а также сделать возможным эффективный статистический анализ - как медицинский, так и финансово-экономический - имеющейся информации. Иногда также требуется проводить экспертизу каких-либо фактов группой специалистов. Описание конкретного примера системы для решения подобных задач можно найти в [2]. В этой работе также подробно обосновывается целесообразность разработки модели данных, ориентированной на задачи мониторинга, и описаны принципы, на которых она должна основываться.
2. Геологический мониторинг. Основным свойством геологической информации является пространственная и временная приуроченность данных. В соответствии с множеством изучаемых процессов проводится комплекс периодических исследований геологических процессов и явлений на постоянных полигонах и в отдельно взятых точках некоторого региона. Разные процессы имеют разную скорость развития, в связи с чем некоторые из них рассматриваются как стационарный фон, а другие нуждаются в исследованиях разной (от столетий до долей суток) периодичности. Результаты исследований накапливаются в единой информационной системе для последующего анализа.
3. Контроль качества. При производстве сложных изделий требуется проводить их испытания разных видов (например, термические, механические и проч.), измеряя ряд параметров и должным образом реагировать на отклонения от заданных значений, в случае необходимости проводя дополнительную диагностику и исследования.
Легко видеть, что во всех описанных случаях имеется некоторое множество объектов реального мира. Имеется также ряд наблюдателей, которые фиксируют некоторый набор параметров этих объектов. Само наблюдение также может выступать в качестве объекта для наблюдения - как в случае с оценкой эффективности терапии или экспертными заключениями. Задачей является наблюдение над объектами, регистрация и контроль их параметров, исследование корреляций или других зависимостей между ними, прогнозирование поведения этих зависимостей, отслеживание критических ситуаций, выработка оценок и решений, оптимальных в текущей ситуации.
не было специальной цели написания
Итак, не было специальной цели написания данного обзора. Цель была другая. Требовалось найти СУБД для системы, которая должна решать одну из основных задач автоматизации Сбербанка - лицевые счета клиентов. Поиски привели к тому, что пришлось пересмотреть несколько доступных на сегодня свободных СУБД. В результате сложилось определенное впечатление, которое и приведено ниже.
В обзоре отсутствуют объяснения, почему в качестве платформы автоматизации была выбрана ОС Linux. Это тема другой статьи. Если коротко, то Linux это Unix-like операционная система с сетевой оконной графической системой X Window. Все компоненты системы, включая исходные тексты, распространяются свободно. Здесь же перечислю те требования, которые я предъявлял к СУБД, с позиций ее применения в упомянутой системе:
реальный многопользовательский режим;
транзакционная защита от сбоев;
возможность "плотного" хранения данных. (Имеется в виду возможность хранения множества типов, например языка С, и возможность их обработки. Требование связано с объемом и составом данных. Примерный объем 50000-100000 записей лицевых счетов и 300000-500000 записей о движении денег.);
желательно, чтобы СУБД работала в режиме клиент-сервер через TCP/IP;
возможность работать с базой из процедурного языка, лучше из С или С++. Желательно иметь доступ типа SQL;
и, наконец, СУБД должна обладать достаточной "скорострельностью" (Например, задача получения баланса, т.е. сложение массива чисел (см. объем базы) на процессоре 486DX при 8 Мб и средних по скорости IDE дисках не должна занимать более 5 мин.)
Возможно, последнее требование сформулировано не совсем корректно, тем более, что все это можно улучшать за счет аппаратуры. Но интуитивно должно быть понятно, что я хотел сказать.
Замечу, что предыдущий вариант системы был сделан в SCO UNIX с использованием коммерческой СУБД Raima Data Manager (RDM), известной больше под названием dbVista 3.21. И, надо сказать, RDM показала себя с лучшей стороны. Она удовлетворяла практически всем перечисленным требованиям, если не считать отсутствия режима клиент-сервер.
Кстати, загрузочная прикладная программа, собранная под управлением SCO Unix с библиотекой RDM, с успехом работала в Linux (через систему совместимости iBCS) и гораздо быстрее, чем в родном ей SCO UNIX. По некоторым данным, в Linux можно изготовить объектный модуль (в формате COFF), который линкуется с библиотекой из SCO Unix. Я не проверял, если кто знаком с этой технологией, пусть поделится. Если это так, то получается, что Linux позволяет работать с SCO-версией RDM, и при этом SCO Unix не нужен вообще.
Тому, кто знаком с RDM, должны быть понятны мои пристрастия. Среди требований ничего не сказано об интерфейсе с пользователем. Этот интерфейс логичнее, проще и стандартнее сделать другими средствами, например, на Tcl/Tk для X Window. Поэтому не обсуждаем эти вопросы.
Предлагаемая программа исследований
В этом разделе обсуждаются темы исследований, заслуживающие значительного внимания. Обсуждавшиеся выше движущие силы обосновывают каждую из этих тем исследований. Для упрощения мы группируем темы в пять основных направлений и обсуждаем каждое из них по очереди.
Представления идентифицируемых сложных объектов в реляционной базе данных
Евгений Григорьев ()
Из названия следует, что речь в статье будет идти о совмещении объектной и реляционной систем. Надо отметить, что эта тема послужила поводом для написания большого количества работ. Спектр мнений представленный в этих работах чрезвычайно широк и, начиная с идеи о практической идентичности данных моделей, требующей лишь незначительного расширения одной из них, кончается явным противопоставлением, ведущим к выводу о невозможности их объединения. Критике в той или иной мере подвергаются обе модели.
Не вдаваясь в подробности можно сказать, что недостатки каждой модели неразрывно связаны с их преимуществами и фактически противоположны друг другу. Реляционные системы (R-системы) критикуются за отсутствие гибкости, являющейся следствием формальностии (а следовательно, строгости и стабильности), а объектные (O-системы) - за отсутствие формальности, являющейся следствием гибкости. [1,6,7,8, 19,21,22,23]
Данная работа исходит из практической завершенности как реляционной так и объектной концепций. Цель данной статьи - показать, что эти концепции абсолютно не противоречат друг другу и не требуют каких-либо изменений для того, что бы использоваться в общей системе, обладающей всеми свойствами как объектных,так и реляционных систем.
Это идея основывается на следующих утверждениях:
Один и тот же набор данных может одновременно описываться несколькими разными моделями
Реляционная и Объектная модели - разные модели.
Структуру любой сложности можно нормализовать.
Рассмотрим эти утверждения подробнее
В основной части этой статьи
В основной части этой статьи я цитировал [12] в связи с определением вычислимой функции как функции, которую можно закодировать с использованием циклов WHILE. Вслед за этим определением в [12] говорится следующее:
Циклы FOR (для которых имеется фиксированное ограничение на число итераций) являются частным случаем циклов WHILE, так что вычислимые функции можно также закодировать с использованием некоторой комбинации циклов FOR и WHILE. Простейшим примером функции, являющейся вычислимой, но не примитивно-рекурсивной, является функция Акермана (Ackermann).
Позвольте мне кратко развить эти замечания. Во-первых, функция называется рекурсивной в том и только в том случае, когда она «может быть получена [sic] путем использования конечного числа операций, вычислений или алгоритмов» [11]. (Заметим, что здесь термин рекурсивный используется не в обычном смысле языков программирования; в действительности, как кажется, он используется ровно в том же смысле, что и термин вычислимый, как он определялся ранее.) Во-вторых, функция называется примитивно-рекурсивной в том и только в том случае, когда ее можно закодировать с использованием только циклов FOR [12].
Далее, я не знаю, в каком смысле функция Акермана называется выше «простейшим примером» функции, являющейся рекурсивной (или, во всяком случае, вычислимой), но не примитивно-вычислимой. Однако для интереса я привожу здесь определение этой функции (замечу, что это определение является рекурсивным в обычном смысле языков программирования). Вот оно: пусть x и y обозначают неотрицательные целые числа. Тогда функция Акермана A(x,y) может быть определена следующим образом:
OPERATOR A ( X NONNEG_INT, Y NONNEG_INT ) RETURNS NONNEG_INT ;
RETURN ( CASE
WHEN X = 0 THEN Y + 1
WHEN Y = 0 THEN A ( X - 1, 1 )
ELSE A ( X - 1, A ( X, Y - 1 ) )
END CASE ) ;
END OPERATOR ;
Предостережение: Пожалуйста, не пытайтесь выполнить этот алгоритм на реальной машине даже для не очень больших значений x и y.
В целях придания большей ясности я отредактировал (иногда радикально) большую часть цитат, используемых в этой статье.
Естественно, здесь я ограничиваюсь двузначной логикой.
Относительно «теоретико-множественной семантики и семантики вычислительного языка» см [8].
Пример Брокеров Объектных Запросов.
Доступно широкое множество способов реализации конкретных ORB-ов. Далее будут приведены примеры таких реализаций. Следует иметь ввиду, что конкретный ORB может быть реализован сразу несколькими способами.
Прямое выполнение с откатом
Один их возможных механизмов реализации функциональных update-выражений - это замена таких выражений традиционными (не функциональными) update-выражениями с последующим откатом к исходному состоянию данных. Несколько похожие идеи возникали и в контексте объектно-реляционных баз данных [].
Реализованный во многих XML-СУБД [, , , ] язык модификации XML-данных можно использовать для изменения состояния данных, а язык XQuery - для вычисления запроса над измененным состоянием. Заимствование в качестве синтаксиса функциональных update-выражений синтаксиса обычных update-выражений делает такую замену вполне естественной. Еще раз рассмотрим из раздела 2:
for $r in doc("db.xml")/db/movie[gender="fiction"]/review transform replace $d in $r//director with <a href="{doc("b")//person[name=$d/@name]/homepage/text()}"> {$d/text()} </a>
Такой запрос можно вычислить, перезаписав его в виде трех выражений языка XQuery и языка модификации XML-данных (на примере синтаксиса языка модификации XML-данных, реализованного в XML СУБД Sedna).
1-ый шаг:
UPDATE replace $d in doc("db.xml")/db/movie[gender="fiction"]/review $r//director with <a href="{doc("b")//person[name=$d/@name]/homepage/text()}"> {$d/text()} </a>
2-ой шаг:
doc("db.xml")/db/movie[gender="fiction"]/review
3-ий шаг:
ROLLBACK
Первое update-выражение изменяет состояние данных, второе выражение вычисляется над измененным состоянием данных и формирует результат запроса. Третье выражение "придает" функциональную семантику вычислению первых двух выражений - откатывает базу данных к начальному состоянию. Очевидно, что из-за побочных эффектов от вычисления первого выражения теряется возможность доступа к начальному состоянию данных во втором выражении.
Эффективность вычисления такой последовательности запросов определяется эффективностью реализации update-выражений в XML-СУБД и эффективностью вычисления операции ROLLBACK. Если реализация update-выражений удовлетворяет требованию произвольного доступа к данным, то и описанный подход отвечает этому требованию.
Такой подход к реализации расширения языка XQuery функциональными update-выражениями ограничивает их семантику тем, что выражения расширенного языка не обеспечивают доступ к исходному состоянию данных.
Проблемы качества данных
С последствиями грязных данных мы сталкиваемся в своей повседневной жизни. Мы получаем массу почтовых отправлений с орфографическими ошибками в именах, множество посланий с разными вариантами одного и того же имени, массу писем, адресованных людям, которые давно переехали, банковские уведомления о многочисленных расходных операциях (в то время как деньги со счета снимались лишь однажды) и т.д. К грязным данным относятся отсутствующие, неточные или бесполезные данные с точки зрения практического применения (например, представленные в неверном формате, не соответствующем стандарту). Грязные данные могут появиться по разным причинам, таким как ошибка при вводе данных, использование иных форматов представления или единиц измерения, несоответствие стандартам, отсутствие своевременного обновления, неудачное обновление всех копий данных, неудачное удаление записей-дубликатов и т.д.
Очевидно, что результаты запросов, добычи данных или бизнес-анализа над хранилищем, содержащим большое число грязных данных, не могут считаться надежными и полезными. Только сейчас предприятия начинают внедрять инструменты очистки данных. Представленные сегодня на рынке средства очистки данных (например, продукты компаний Vality/Ascential Software, Trillium Software и First Logic) помогают выявлять и автоматически корректировать некоторые наиболее важные типы данных, в особенности, имена и адреса людей (с использованием национального каталога имен и адресов). Однако этим средствам предстоит пройти еще долгий путь, поскольку сегодня они не умеют работать со всеми типами грязных данных, и далеко не все компании используют даже имеющиеся средства. Более того, большинство предприятий не внедряет надежные методики и процессы, гарантирующие высокое качество данных в хранилище. Недостаточное внимание, уделяемое качеству данных, обусловлено отсутствием понимания типов и объема грязных данных, проникающих в хранилища; влияния грязных данных, принятие решений и выполняемые действия; а также тем фактом, что продукты очистки данных, представленные на рынке, не слишком хорошо рекламируются или слишком дорого стоят.
Для того чтобы начать уделять необходимое внимание качеству данных в своих хранилищах, предприятиям, прежде всего, нужно разобраться в многообразии возможных грязных данных, источниках их появления и методах их обнаружения и очистки. Разумной стартовой точкой может служить [1]. В этой статье представлена по существу исчерпывающая таксономия 33 типов грязных данных и также разработана таксономия методов предотвращения или распознавания и очистки. Таксономия грязных данных демонстрирует многие типы грязных данных, с которыми не справляются сегодняшние средства очистки. В ней также указываются различные типы грязных данных, которые могут быть автоматически обнаружены и очищены, или даже появление которых может быть предотвращено. Однако, к сожалению, в статье демонстрируется большое число видов грязных данных, которые непригодны для автоматического обнаружения и очистки, и появление которых невозможно предотвратить. Например, по ошибке в базу данных вводятся данные о том, что возраст некоторого человека составляет 26 лет, в то время как в действительности ему 25 лет; или вводится имя человека Larry Salcow, а на самом деле оно пишется как Larry Salchow; или же адреса > и > являются старым и новым адресами одного и того же человека. Эти грязные данные появляются по причинам ошибки при вводе данных, неудачным обновлением адреса человека или неудачной стандартизации представления имени. Понятно, что никакое программное средство (и даже человек) не смогут обнаружить, что эти данные являются грязными. Конечно, теоретически можно произвести дорогостоящую перекрестную проверку данных из разных источников (файлов или таблиц), которые содержат информацию о возрасте, имени и адресе одного и того же человека.
Далее, предприятиям требуется оценить стоимость наличия грязных данных; другими словами, наличие грязных данных может действительно привести к финансовым потерям и юридической ответственности, если их присутствие не предотвращается, или они не обнаруживаются и не очищаются.
Предположим, что компания осуществляет рассылку рекламных материалов на 100 тыс. адресов по цене 2 долл. за адрес. Если 2% адресов являются грязными, доставить по ним материалы не удастся. Две тыс. почтовых отправлений обойдутся в 4 тыс. долл. (Для простоты проигнорируем тот факт, что на самом деле 98% массовых почтовых отправлений, даже доставленных должным образом, все равно останутся без ответа.)
Тот факт, что наличие грязных данных влечет расходы, не обязательно означет необходимость предотвращения грязных данных или их распознавания и очистки. Дело в том, что должна оцениваться также и стоимость предотвращения или распознавания и очистки грязных данных. Если требуется двухчасовое выполнение процедуры очистки данных для коррекции адресов из нашего примера, и компания уже расплагает средством очистки данных, то имеет смысл потратить время на исправление адресов перед началом рассылки. Однако будет лучше ничего не делать с неверными адресами, если можно нанять на 100 дней и за 10000 тыс. долл. человека, который вручную проверит правильность всех адресов, руководствуясь телефонным справочником или базой данных регистрации транспортных средств.
Проанализируем стоимость предотвращения, обнаружения и очистки грязных данных. Появление грязных данных любого типа можно предотвратить или распознать и очистить (автоматически или вручную), но это влечет расходы. В общем случае для каждого типа грязных данных имеется несколько, отличающихся по цене, способов предотвращения или обнаружения и очистки недействительных данных. К примеру, средства управления транзакциями в системах РБД предотвращают появление некоторых типов грязных данных, обуславливаемых потерянными обновлениями, а также грязным и неповторяемым чтением [1]. Определение ограничений целостности, таких как типы данных, ограничения уникальности, запрета наличия неопределенных значений и внешних ключей заставляет систему РБД автоматически поддерживать целостность данных при выполнении операций вставки, обновления и удаления.
Эти средства являются частью системы РБД, и их выполнение занимает относительно небольшую часть машинного времени. Для выявления неправильно написанных слов имеет смысл запустить процедуру проверки орфографии. Для исправления неверно написанных имен и адресов можно использовать справочник, из которого можно почерпнуть и дополнительную информацию, в частности, почтовый индекс, название административного округа и т.д. Для принятия рекомендаций программных средств обычно требуется вмешательство человека. Можно обеспечить в значительной степени автоматическое обнаружение грязных данных некоторых типов, но гарантировать абсолютную корректность можно не всегда. Например, можно использовать средство автоматической проверки вхождения числового значения в указанный диапазон, для гарантии того, что возраст человека находится в диапазоне от 18 до 67 лет. Чтобы гарантировать отсутствие ошибок ввода, можно поручить нескольким людям проверку и перепроверку вводимых данных.
Стоимость исправления грязных данных зависит также от общего объема данных и пропорции грязных. Очевидно, что для проверки файла с большим числом записей и полей потребуются более серьезные усилия, чем для файла с меньшим числом записей и полей. Стоимость обнаружения и исправления одного элемента грязных данных в единственном поле единственной записи зависит от типа грязных данных.
Несомненно, что большинство предприятий сегодня не предпринимает достаточных усилий для обеспечения высокого качества данных в своих хранилищах. Для обеспечения высокого качества данным предприятиям нужно иметь процесс, методологии и ресурсы для отслеживания и анализа качества данных, методологию для предотвращения или обнаружения и очистки грязных данных и методологии для оценки стоимости грязных данных и затрат на обеспечение высокого качества данных. В Ewha Women's University разработан прототип инструментального средства DAQUM (Data Quality Measurement), предназначенного для отслеживания большинства типов грязных данных и приписывания разным типам грязных данных количественной меры качества данных в зависимости от особенностей приложений [2].В этом направлении нужно предпринимать дополнительные усилия.
Проблемы производительности и масштабируемости
В системах РБД для выборки небольшого количества нужных записей без полного сканирования таблицы или базы данных используются различные методы доступа, такие как индексы на основе хеширования или B+-деревьев. Такие методы доступа весьма эффективны при выборке по одному ключевому полю (или небольшому числу полей), когда результаты представляют собой малую часть таблицы. Примерами подобных запросов являются: >, > или >. Для быстрого ответа на такие запросы можно создать индексы: на столбце > таблицы >, на столбце > таблицы > и на столбцах > и > таблицы > соответственно.
Однако методы доступа в общем случае не помогают при ответе на запросы, результатами которых является значительная часть таблицы. Примерами являются запросы: >, > и >. Кроме того, методы доступа не приносят пользы, если значения столбца часто изменяются, поскольку такие изменения требуют перестройки методов доступа. Это примеры > запросов, для выполнения которых методы доступа в системах РБД оказываются бесполезными.
Помимо подобных > запросов существуют два класса операций, для которых методы доступа в системах РБД становятся бессильными. К первому классу относятся операции >, предусматривающие группировку всех записей таблицы и применение к сгруппированным записям агрегатных функций (среднего значения, общего числа, суммы, минимального или максимального значения). Этот тип операций важен в таких приложениях как анализ данных Web-журналов, сегментации данных о заказчиках и т.д. Различные методы, связанные с проблемой эффективности операций этого класса, анализируются в [7], включая сжатие данных, метод хранения таблицы по полям (хранение каждого поля таблицы как отдельного файла), предварительные вычисления (гиперкубов OLAP, сводных таблиц) на основе детализированных данных, нормализацию (разбиение таблицы на несколько более мелких таблиц) и параллельную обработку. На рынке имеются продукты MaxScan и Ab Initio, предназначенные для решения проблем производительности и масштабируемости при выполнении данного типа операций.
В MaxScan применяется метод хранения таблиц по полям, методы хеширования для группировки и агрегирования записей, а также методы параллельной обработки. Производительность и масштабируемость при выполнении агрегатных операций в 10-20 раз превышают показатели систем РБД. Ab Initio является средством ETL, в котором в механизме трансформации данных используются методы повышения производительности.
К другому классу относится операции >, читающие и/или записывающие файл(ы) целиком. Этот тип операций важен на этапе требующем больших временных затрат > при создании хранилища данных или на этапе > при автоматическом извлечении знаний (добыче данных) из имеющихся источников [8]. Этап преобразования данных включает трансформацию формата и представления данных в заданных полях (изменение единицы измерения, изменение формата даты и времени, изменение аббревиатуры и т.д.), слияние двух или более полей в одно, расщепление поля на два или более полей, сортировку таблицы, построение обобщенной таблицы из таблиц, содержащих детализированные данные, создание новой таблицы путем соединения двух или более таблиц, слияние двух или более таблиц в одну, расщепление таблицы на две или более и т.д. К этапу подготовки данных относятся преобразование данных заданного поля в цифровой код (в нейронных сетях), преобразование непрерывных цифровых данных в заданном поле в категорические данные (например, возраст, превышающий 60 лет, считается >), добавление к записи нового поля, взятие из таблицы образцов данных, репликация в таблице некоторых записей (для достижения желаемого распределения записей) и т.д. Более подробное обсуждение этих операций приводится в [9].
Сегодня операции перемещения файлов находятся в почти полной зависимости от последовательных операций систем РБД над файлами, т.е. чтения одного или более файлов, создания временного файла и записи результирующего файла или файлов. Частота выполнения подобных операций и объем используемых данных может сделать оправданным применение сервера преобразования/подготовки данных.
В идеале такой сервер может состоять из нескольких параллельно работающих процессоров. Независимо от конфигурации процессора на нем должны выполняться программные средства преобразования/подготовки данных, спроектированные для параллельной обработки. Когда это оправданно, нужно применять конвейерную параллельную обработку, при которой получение частичных результатов одной операции инициируют выполнение другой операции без потребности ожидания завершения первой операции. Конвейерная параллельная обработка устраняет потребность в записи во временный файл полных результатов одной операции и в их чтении следующей операцией, что позволяет сэкономить два ввода-вывода файла. Для создания сводных таблиц вместо > функций системы РБД имеет смысл использовать механизм быстрой сортировки, такой как SyncSort, или механизм быстрого агрегирования, такой как MaxScan. Кроме того, для выполнения вычислений > (выборка образцов, преобразование формата или представления данных и т.д.) имеет смысл разбить файл на несколько подфайлов и назначить каждому из них отдельный процессор для обеспечения параллельной обработки.
Проблемы разработки приложений с применением ПО "двойного назначения"
Какие же ошибки допускают разработчики в среде Lotus Notes и администраторы Lotus Domino? Все ли они приводят к невозможности нормальной эксплуатации ИС? Каким образом ИС деградирует в результате тех или иных ошибок разработки и администрирования? Существует ли заранее известная стратегия "выигрыша в Domino", то есть успешного администрирования и разработки? Попытаемся ответить на эти вопросы.
Наложение абстракций
Начнем с разработки и вновь обратимся к предложенному делению ПО на три группы. В случае, когда разработка имеет место в продуктах первой группы, она (и ее результат) целиком и полностью остается в поле тех понятий и абстракций, с которыми работает пользователь базового ПО. Действительно, если разработчик желает, например, автоматизировать заполнение свойств документа при его редактировании и сохранении новой версии, то он пишет макропрограмму, которая оперирует сама, и, что важнее, предлагает пользователю работать с полями, текстом, комментариями, исправлениями, абзацами и т. п. Для пользователя не вводятся новые объекты работы и термины для них. В крайнем случае, новым термином называется уже существующий объект.
В случае разработки приложения для работы с сетевой базой данных (БД) через сервер приложений, разработчик целиком и полностью изолирует пользователя от реальных объектов (таблицы, кортежи, SQL-запросы и т.п.) при помощи введенных им абстракций: учетных карточек, документов и так далее. И это, безусловно, правильно.
При создании приложений Lotus Domino у разработчика зачастую появляется соблазн использовать второй подход. Действительно, зачем пользователю работать с репликами БД, видами и агентами? Его ведь интересуют документы, поля и действия над ними. Такой подход не учитывает, что Lotus Notes уже содержит в себе абстракции пользовательского уровня. Документы и поля - это абстракции записей в неструктурированной базе данных, виды - выборок записей по определенному критерию, реплики - синхронизируемых БД с механизмом разрешения конфликтов одновременного совместного доступа к различным копиям одной информации и т.
д. Введение второго уровня абстракций с большой вероятностью может привести к полной неработоспособности созданного приложения. Почему? Как и любое другое ПО Lotus Domino и Notes оптимизированы для работы со своими структурами и абстракциями. И отличие его от RDBMS состоит не только в способе организации доступа и хранения данных, но и в том, что последние не содержат абстракций пользовательского уровня, предоставляя разработчику свободу их выбора (и наименования), а Lotus Notes - содержит, и, что очень важно, рассчитан на работу именно с этими пользовательскими абстракциями.
Хорошо это или плохо? И то, и другое - это особенность, с которой надо считаться. Конечно, набор абстракций, которые предлагает Lotus Notes не всегда в точности соответствует тому, что хотелось бы предоставить конечному пользователю. Но эту проблему можно решить путем обучения пользователей. Да, это почти всегда будет стоить дороже разработки собственной модели с набором понятий и абстракций и ее реализации, но это, по-видимому, единственный путь получить работающее приложение. Что, по-вашему, выберет заказчик более дорогую систему, к которой надо привыкать или более дешевую, которая ему уже знакома, если первая работает, а вторая нет? Ответ очевиден. И, видимо, следует убедить заказчика в необходимости обучения, а не пытаться оживить неработающее приложение путем наращивания мощности аппаратной платформы, перепроектирования системы или написания заплат(как правило - не документированных), которые, как показывает практика, только усугубляют ситуацию.
Вывод из вышесказанного таков - необходимость обучения пользователя работе с Lotus Notes - это признак, общий для ПО второй и третьей группы, и попытка избежать обучения путем введения нового уровня абстракций для пользователя не приведет к ожидаемому результату, так как не учитывает особенностей, присущих используемому ПО.
Однопользовательское ПО в сети
Еще одна проблема разработки в Lotus Domino и Notes также связана с кажущейся простотой, присущей ПО третьей группы.
По аналогии с макропрограммами в однопользовательском ПО, приложения Lotus Notes также зачастую не учитывают сетевой сущности этого продукта. Ситуация усугубляется еще и тем, что в Notes действительно можно писать однопользовательские несетевые приложения. И они будут работать. Не в сети. И пока ими будет пользоваться один человек.
Некоторые разработчики уверены, что они должны правильно запрограммировать логику работы пользовательского приложения, а работу его в сети, "всякие там репликации" должны обеспечить администраторы, или, еще лучше, сервер Lotus Domino. Это не так. Разработчик всегда должен учитывать те условия, в которых будет эксплуатироваться его приложение. Его работа в сети накладывает дополнительные ограничения на усилия разработчика при программировании, чем, безусловно, усложняет его задачу многократно. Однако отмахнуться от этих проблем нельзя - персональное приложение просто не заработает в сети. Разработчик, таким образом, должен знать возможности Lotus Notes как сетевой технологии, то есть технологии реализации архитектуры "клиент-сервер", модели сетевого взаимодействия OSI/ISO, и т. д.
У этой ошибки возможно и другое проявление, несколько перекликающееся с первой ошибкой, описанной в предыдущем параграфе - наложение абстракций. Иногда разработчик, создавая сетевое приложение самостоятельно реализует в нем те функции, которые уже обеспечиваются клиентским ПО, сервером приложений или используемыми протоколами. При этом, естественно, серверные средства требуется в лучшем случае отключить, а в худшем - они становятся помехой для функционирования приложения. Проблема заключается не только в том, что разработчик выполняет лишнюю работу, но и в том, что имеющиеся в системе средства всегда намного (на порядки) эффективнее, чем "самодельные" аналоги. Почему? Системные сервисы реализуются при программировании на языке высокого уровня и являются отлаженной интегрированной частью всего ПО. Разработчики же создают свои заменители на макроязыке еще более высокого уровня, всегда интерпретируемом (иногда из исходного текста, иногда - из промежуточного байт-кода).
Если к этому добавить еще и то, что в большинстве случаев разработчики прикладного ПО не имеют достаточного опыта и знаний по созданию сетевых многопользовательских приложений низкого уровня, каковыми являются системные сервисы, то полная неработоспособность таких приложений или их крайне неэффективная работа оказываются печальным, но закономерным итогом трудоемкой и дорогостоящей разработки.
Решением указанной проблемы может быть обеспечение тесного взаимодействия программистов и опытных системных администраторов на всех этапах создания прикладного ПО для Lotus Domino/Notes, а также обязательное обучение разработчиков технологии проектирования и разработки именно сетевых программных средств. Со своей стороны, администраторы должны предоставлять разработчикам всю информацию о сервисах, которые могут быть ими использованы, конфигурации сети и ее влиянии на эксплуатируемое ПО.
Вывод из этого раздела можно сформулировать так: при разработке приложений в Lotus Domino/Notes необходимо учитывать сетевую многопользовательскую специфику этого ПО. И, если в случае персонального приложения, Lotus Notes проявляет себя как ПО первой группы, то в случае сетевого - как второй. Такая двойственность является расплатой за универсальность и относительную дешевизну.
"Изощренные решения"
Изощренным решением (sophisticated solution) обычно называют нетрадиционное, сложное, но, зачастую, красивое решение какой либо проблемы. Однако, применительно к Lotus Domino и Notes (как и к любому другому достаточно сложному ПО), такие решения таят в себе и потенциальную опасность. Проблемы, с этим связанные, возникают на границе доменов ответственности администраторов и разработчиков, что дополнительно усложняет их выявление и устранение.
В лицензионном соглашении IBM для ПО Lotus Domino или Notes (как и в любом другом лицензионном соглашении сегодня) сказано: "Данное ПО - достаточно сложное, и в нем наверняка есть ошибки. Мы это признаем и заранее Вас предупреждаем." Это означает, что даже без постороннего вмешательства (снаружи или изнутри, то есть администратора или разработчика) система находится в состоянии неустойчивого равновесия.
Внутренние ошибки (сбой памяти, ошибки программистов и т. п.) способны привести к сбою в случае, например, перехода системы в определенный режим работы или пребывания в каком-либо режиме в течение определенного времени.
Разработчики обычно стараются постоянно улучшать свои приложения. И заказчик обычно склонен добиваться удовлетворения всех своих требований. В результате, зачастую, складывается ситуация, когда для реализации какой-либо функции требуется то самое "изощренное решение". Это может быть код в несколько десятков строк, код, который делает что-то такое, чего не было предусмотрено в системе, конфигурация или параметр, которые не описаны в документации и т. д. Часто подобные решения применяются, так как иначе какое-либо требование осталось бы неудовлетворенным. Однако, в свете вышесказанного, следует понимать, что подобные эксперименты хороши для исследования потенциальных возможностей ПО или демонстрации потенциальных возможностей программиста. Но в случае промышленной версии надо (в разумных пределах, разумеется) стремиться к принципу: "Чем проще - тем надежнее".
Применительно к Lotus Domino/Notes - это правило означает следующее. Любую функцию следует реализовывать, по возможности, с помощью простых действий (Simple Actions). Если это невозможно, то писать простой и короткий код, который всесторонне отлаживать во всех режимах работы системы. Кроме того, полезно иметь упрощенный вариант приложения, который бы исключал сложные функции, заменяя их рядом простых. Опять же, заказчик предпочтет приложение, в котором надо чаще щелкать мышкой, вводить что-либо с клавиатуры и т. п., если оно работает, - красивой, удобной и лаконичной программе, которая пригодна только для демонстрации возможностей ПО и разработчиков.
Отличным образцом для подражания могут служить приложения, которые поставляются вместе с ПО Lotus Domino: почтовый ящик, адресная книга, телеконференция и т. д. Конечно, все они далеки от идеала (по удобству использования, скорости работы, красоте исполнения), но они работают.И в этом их главное преимущество.
Проблемы самонастраивающейся оптимизации запросов
При создании первого прототипа LEO выявилось несколько серьезных исследовательских проблем, решение которых требуется для какого-либо практического применения оптимизатора в коммерческом продукте. Обсудим эти проблемы и возможные подходы к их решению.
Стабильность и сходимость. В модели мощности промежуточных результатов, усовершенствованной за счет обратной связи, должна приниматься во внимание неполная информация. Если некоторые мощности могут устанавливаться за счет обратной связи запроса (их можно считать надежными фактами), то другие выводятся из статистики и предположений моделирования (они являются недостоверными знаниями). Скорость обучения системы существенно зависит от рабочей нагрузки и точности статистики и предположений.
Предположение о независимости предикатов в то время, когда в действительности между данными имеется корреляция, как правило, приводит к заниженным оценкам мощности промежуточных результатов, используемых оптимизатором для определения стоимости QEP. Такая недооценка вынудит оптимизатор предпочесть план, основанный на недостоверных знаниях, плану, опирающемуся на надежные факты. Недооценка мощностей может привести к полному анализу пространства поиска; система будет принимать решение только после выбора и изучения всех QEP, содержащих заниженные оценки. Однако завышенные оценки могут привести к локальному минимуму (т.е. к неоптимальному QEP); оптимизатор предпочтет другие QEP плану с завышенными оценками. Поэтому завышенные оценки вряд ли удастся обнаружить и скорректировать.
Чтобы достичь разумного уровня стабильности, самонастраивающимуся оптимизатору следует, например, прежде чем приступать к производству, сначала использовать исследовательский режим. В начале в этом будет иметься больший уровень риска выбора многообещающих QEP на основе недостоверных знаний. Это даст возможность проверить достоверность модели и собрать надежные факты о распределении данных и рабочей нагрузке. Во втором, операционном режиме выбор QEP будет основываться на опыте.
В этом режиме QEP, основанные на надежных фактах, предпочитаются перед более дешевыми QEP, опирающимися на недостоверные знания. По-видимому, переход от одного режима к другому должен быть постепенным, напоминающим методы моделируемой сходимости [17] в машинном обучении.
Для преодоления локального оптимума, вызванного завышенными оценками, необходимо исследовать недостоверные знания, используемые для вероятно неоптимальных, но многообещающих QEP, например, путем синхронного или асинхронного взятия образцов [10].
Выявление и использование корреляции. В практических приложениях между данными часто имеется корреляция. Например, в базе данных автомобилей селективность конъюнкции (make = «Honda» and model = «Accord») не равна произведению селективностей предикатов make = «Honda» и model = «Accord», поскольку между столбцами make и model имеется корреляция — только Honda выпускает модель Accord. Поскольку наличие корреляции нарушает предположение о независимости, в современных оптимизаторах оценки селективности для предикатов, в которых присутствует корреляция, могут отличаться от реальных значений на несколько порядков. Наш подход обеспечивает возможность выявлять и исправлять такие ошибки.
Наличие корреляции порождает много сложных проблем. Во-первых, существует много типов корреляции, от функциональных зависимостей между столбцами, главным образом, ссылочная целостность, до более тонких и сложных случаев, таких как специфическое для приложения ограничение, что товар поставляется не более чем 20 поставщиками. Во-вторых, в корреляции могут участвовать более чем два столбца и, следовательно, более чем два предиката в запросе, причем подмножества этого множества столбцов могут обладать разными степенями корреляции. В-третьих, один запрос может свидетельствовать только о том, что два или более столбцов коррелируют по конкретным значениям. Для сложных запросов, включающих несколько предикатов, задача определения подмножеств предикатов, между которыми имеется корреляция, и ее степени может оказаться очень сложной.
Еще одна сложная исследовательская проблема заключается в обобщении корреляции конкретных значений на взаимосвязи между столбцами: сколько требуется различных значений из нескольких выполняемых запросов, включающих предикаты на одних и тех же столбцах, чтобы можно было с уверенностью сделать вывод, что между этими столбцами вообще имеется корреляция, и определить степень корреляции? Вместо того, чтобы дожидаться завершения выполнения этих многочисленных запросов, процедура выявления корреляции могла бы распознавать многообещающие комбинации столбцов (даже из различных таблиц), на которых утилита сбора статистики собрала бы затем многомерные гистограммы. Кроме того, наблюдаемая информация может использоваться для выявления ошибок в модели мощности промежуточных результатов, наполнения статистики базы данных или уточнения неверных оценок путем создания дополнительного уровня статистики.
Необходимость в повторной оптимизации. Как уже обсуждалось выше в разделе, безотлагательное обучение может привести к изменению плана запроса во время его выполнения, если реальные мощности значительно отличаются от их оценок. Однако новый план может сам по себе оказаться достаточно дорогим, если нет возможности эффективно использовать ранее созданные TEMP. Оптимизатор обнаружит это во время повторной оптимизации, но могут оказаться существенными расходы на саму повторную оптимизацию. Поэтому исключительно важно, не инициируя повторную оптимизацию, уметь определять, когда имеет смысл ее выполнять.
В [12] различие между предполагаемыми и реальными мощностями используется в качестве эвристики для определения того, нужно ли выполнять повторную оптимизацию. Однако вопрос состоит не в том, насколько неточны оценки оптимизатора, а в том, является ли план неоптимальным при новых значениях мощности и являются ли различия в стоимости настолько существенными, чтобы оправдать расходы на повторную оптимизацию. В одной из эвристик рассматривается природа операций плана и оценивается вероятность того, что изменение мощности входных данных операции сделает ее неоптимальной.
Или же можно усовершенствовать оптимизатор таким образом, чтобы он предсказывал не только оптимальный план, но и также и тот диапазон селективности каждого предиката, внутри которого план является оптимальным. Предсказывать «чувствительность» любого плана по отношению к одному произвольному параметру исключительно сложно, поскольку в модели оценок имеются нелинейности.
Нам также требуется ограничить число попыток повторной оптимизации одного запроса, поскольку проблема сходимости в данном случае является еще более серьезной. Нам бы не хотелось, чтобы выполнение запроса превращалось в длинный цикл, в котором опробываются все альтернативные планы прежде, чем достигается успех.
Изучение иной информации. Обучение и адаптация к динамической среде не ограничиваются мощностью и селективностью. При использовании цикла обратной связи может быть обеспечена самопроверка достоверности значений стоимости и других параметров, оцениваемых в настоящее время оптимизатором. Например, основной аспект стоимости, число физических операций ввода/вывода, которое сейчас оценивается вероятностным образом на основе оцененного процента удач в предположении, что каждому приложению доступна часть пула буферов одного и того же размера. Оптимизатор мог бы проверить для данного плана достоверность этих оценок путем слежения за реальным вводом/выводом, реальным процентом удач и реальным числом операций доступа к таблицам. Другим примером является максимальный объем памяти, выделяемый для выполнения в плане конкретной сортировки в плане. Если бы СУБД определила с помощью обратной связи запроса, что операция сортировки не может быть выполнена в основной памяти, она могла бы отрегулировать размер «кучи», предназначенной для сортировки, чтобы избежать внешней сортировки при выполнении таких последующих операций.
Обратная связь не ограничивается службами и ресурсами, потребляемыми СУБД, а распространяется также и на приложения, обслуживаемые СУБД. Например, СУБД могла бы измерить, сколько строк из результата запроса действительно потребляется каждым приложением, и оптимизировать производительность каждого запроса именно для этой части результата путем, например, явного добавления к данному запросу раздела OPTIMIZE FOR <n> ROWS.Подобным образом, обратная связь при выполнении могла бы использоваться для автоматической установки многих устанавливаемых в настоящее время вручную конфигурационных параметров совместно используемых ресурсов. Физические параметры, такие как скорость сети, время доступа к диску и скорость обмена данными с диском, используются для определения веса вклада этих ресурсов в стоимость плана и обычно считаются постоянными после первоначальной настройки. Однако установка этих параметров на основе измеренных значений является более саморегулируемой и более точно фиксирует реальную скорость. Аналогичным образом, распределение памяти между различными буферными пулами, общий размер «кучи» для сортировки и так далее могут настраиваться автоматически с учетом процента удач, наблюдавшегося за последнее время.
Проблемы выбора источников данных
Сегодня проектировщики хранилищ данных проектируют схему базы данных целевого хранилища данных с использованием средств моделирования баз данных. Схема базы данных состоит из таблиц, столбцов (полей) таблиц, типов данных и ограничений столбцов, а также связей между таблицами. Проектировщики также определяют отображения (преобразования) схем источников информации на схему целевого хранилища данных.
Но как проективщики могут убедиться в том, что хранилище данных содержит все данные, нужные приложениям, которые будут над ним выполняться, и не содержит никаких данных, которые приложениям не нужны? Сегодня это основывается на основе догадок опытных проектировщиков. Проектировщикам приходится выявлять потребности в данных (таблицы и столбцы), опрашивая разработчиков приложений, бизнес-аналитиков (людей, которые понимают потребности приложений и бизнеса) и администраторов баз данных. После начального создания хранилища часто оказывается, что в нем отсутствуют данные, требуемые для получения ответов на некоторые запросы, и присутствуют данные, которые никогда не требуются приложениям. Хотя стоимость хранения может быть относительно небольшой, все поля, нужные и ненужные, хранятся в одних и тех же записях и считываются и записываются совместно, что замедляет скорость выборки, увеличивает время обработки, а также приводит к неэффективному использованию среды хранения.
В исследовательской литературе описано много предложений по моделированию хранилища данных в виде репозитария результатов всех выполняемых запросов [4-6]. Авторы этих предложений пытаются найти алгоритмы, которые будут выбирать(для загрузки в хранилище данных) подмножество исходных данных, минимизирующее общее время ответов на запросы. Некоторые из авторов пытаются также минимизировать стоимость обновления хранилища данных. Другими словами, они основываются на предположении, что все запросы к хранилищу данных можно заранее узнать или предсказать и что можно заранее узнать или предсказать все возможные изменения хранилища данных, а следовательно, и исходных источников данных.
Идеальный способ выборки данных для загрузки в хранилище данных состоит в том, что прежде всего определяются все запросы, которые будут генерироваться всеми приложениями, выполняемыми над хранилищем данных, и определяются таблицы и поля, фигурирующие в этих запросах. Определение всех запросов до создания хранилища данных является трудной задачей. Однако это может стать возможным после начального создания хранилища данных за счет регистрации в течение разумного промежутка времени всех запросов, поступающих от приложений. Анализ зарегистрированных запросов может быть использован для тонкой настройки хранилища данных и удаления данных, к которым приложения не осуществляют доступ.
Потенциально полезным и практичным является средство, которое анализирует потребности приложений в данных, автоматически сопоставляет эти потребности со схемами источников данных и выдает рекомендации по составу оптимального поднабора источников данных, которые нужно загрузить в хранилище данных, чтобы в нем находились все нужные данные и не находились какие-либо ненужные. Таким средством является MaxCentra, коммерческая версия которого была выпущена совсем недавно [3]. Функционирование MaxCentra опирается на наличие предварительно построенной базы знаний ключевых слов, которая представляет потребности приложений в данных. Ключевые слова в основном представляют собой неявные указания таблиц и полей, к которым будет осуществляться доступ при выполнении запросов, генерируемых приложением. Такой список ключевых слов может быть обеспечен бизнес-аналитиками или разработчиками приложений, или же он может быть получен автоматически путем анализа запросов от приложений, выполняемых над неоптимизированным хранилищем данных. MaxCentra отталкивается именно от этого и при поддержке и содействии проектировщиков позволяет получить оптимальную схему базы данных для хранилища данных. Работа MaxCentra включает несколько вычислительных этапов, и проектировщик хранилища данных может подтвердить или скорректировать результаты выполнения каждого этапа.Если выполнение MaxCentra основывается только на ключевых словах без учета зарегистрированных запросов, то программа производит стандартную обработку ключевых слов (морфологический анализ, разбиение составных слов, выявление одинаковых слов и т.д.). Затем производится упорядочение таблиц и полей в источниках данных с учетом их релевантности потребностям приложений в данных, группируются таблицы и поля, которые являются избыточными или могут быть порождены одно другим (так что избыточные или несущетственные таблицы и поля могут быть удалены), и группы упорядочиваются с учетом их релевантности потребностям приложений в данных.
Проект
Может быть определен ряд параметров, характеризующих внешнюю обстановку в целом. Для систем, связанных с управлением финансами, такими параметрами могут быть, например, минимальная месячная оплата труда, курс национальной валюты к остальным валютам и другие, доступные всем и не зависящие от контекста параметры. Кроме того, существует ряд параметров, связанных с жизнью конкретного проекта, такие, как дата его создания, используемые ресурсы и т.д. Поэтому сам проект целесообразно рассматривать в качестве объекта - в этом случае его параметры можно задавать с помощью обычных механизмов. Параметры проекта в целом могут использоваться в качестве триггеров, определяющих наступление того или иного события.
Триггер представляет собой глобально определенную процедуру, применяющуюся к вновь проводимому наблюдению сразу после его окончания и устанавливающую значения каких-либо параметров проекта. Механизм триггеров (сторожков - alerters) и хранимых процедур достаточно широко распространен в СУБД, поэтому не стоит подробно останавливаться на этом вопросе. Триггеры, процедуры и функции, специфичные для данного проекта, также являются характеристикой проекта в целом.
Для каждого проекта предопределена таблица размерностей, в которой содержится информация об основных единицах измерений (например, систем СИ, СГС) и преобразованиях между ними. Пользователи проекта могут добавлять свои собственные единицы.
Программные стандарты и их спецификации
Сергей Кузнецов
Программные стандарты являются основой подхода Открытых Систем.
По прошествию многих лет я не могу не согласиться с Юрием
Николаевичем Знаменским (Привет, Юра!) в том, что для создания
распределенных систем необходимо использовать стандартные
транспортные протоколы. В той или иной степени, в зависимости от
прикладной области, но по крайней мере, учитывать наличие
стандартов нужно обязательно. Если... Если вы хотите сохранить
возможность расширения своей системы путем вовлечения в нее
компонентов, разработанных независимо, но с учетом стандартов.
Если... Если вы хотите обеспечить интероперабельность
(новорусское словечко, означающее возможность совместного
функционирования независимо разработанных программных или
аппаратных элементов) компонентов своей системы с компонентами
других систем, разработанных независимо, но с учетом стандартов.
Если... Если вы хотите сохранить возможность переноса приложений
на платформы других производителей, разработанные независимо, но
с учетом стандартов.
Следование набору общепринятых стандартов практически
эквивалентно приверженности подходу Открытых Систем. Сегодня это
уже всем понятно (конечно, тем людям, для которых это
существенно). Непонятно другое: как должен быть оформлен
стандарт, насколько он должен быть формализован, как проверить
соответствие конкретной реализации тому или иному стандарту.
Общее согласие по этому вопросу отсутствует. Имеется масса
различных точек зрения, предлагаются различные решения. И
понятно, что вряд ли удастся принять стандарт для составления
стандартов. Эта заметка направлена на то, чтобы хотя бы частично
разобраться с современными стандартами программных средств, с их
спецификациями, уровнями формализации стандартов и возможностями
проверки соответствия стандарту конкретной реализации. Я не
претендую на общность и излагаю только собственные соображения
без ссылок на авторитеты.
Начнем с положительных (и не очень) примеров. Для меня самым
любимым стандартом является международный стандарт ANSI/ISO языка
Си. Вот почему я его люблю. Этот стандарт опубликован в виде двух
книг. Первая книга представляет собой формальное описание языка,
включая Бекусовские определения синтаксиса и естественно-язычные
(на английском языке) описания семантики соответствующих языковых
конструкций. Вторая книга (Rational) включает подробные
неформальные разъяснения смысла языковых конструкций, введенных в
первой книге. Идея стандарта состоит в том, что параллельно
читаются обе книги. Основная информация содержится в первом томе,
но как только изложение на (полу)формальном уровне становится
непонятным, можно обратиться к соответствующему месту второго
тома и получить неформальные человеческие пояснения. Кроме
определения языковых конструкций Стандарт Си содержит
спецификации основных библиотек, которые должны поддерживаться в
любой стандартной реализации языка Си. Наличие этих спецификаций
исключительно важно само по себе, поскольку, как известно, язык
Си не содержит конструкций, обеспечивающих связь с внешним миром
(в частности, операторов ввода/вывода). Для этой заметки особенно
важно то, что спецификации библиотечных функций в Стандарте Си
вводятся с использованием ранее определенных конструкций языка
Си. Конечно, эти спецификации носят только синтаксический
характер, а семантика библиотечных функций определяется на
естественном языке.
Вторым по качеству, с моей точки зрения, является стандарт языка
баз данных SQL-92. По моему мнению, этот стандарт является лучшим
в компьютерной истории стандартом языков баз данных.
Синтаксические конструкции языка формально определяются
Бекусовскими формулами. Семантика операторов описывается на
естественном языке, но достаточно подробно и точно. Подобно
стандарту языка Си стандарт SQL-92 содержит дополнительную часть,
в которой средствами языка SQL специфицированы необходимые
таблицы-каталоги, которые должны поддерживаться в любой
SQL-ориентированной базе данных. По своей значимости наличие
стандартизованных спецификаций таблиц-каталогов равносильно
наличию стандартизованных спецификаций библиотек в стандарте
языка Си. Еще раз заметим, что спецификации стандарта SQL-92
носят исключительно синтаксический характер. Весь смысл языковых
конструкций и стандартизованных таблиц-каталогов объясняется на
естественном языке.
Наверное, наиболее актуальный набор стандартов в мире
операционных систем составляют стандарты, составленные рабочими
группами POSIX. Первая рабочая группа POSIX (Portable Operating
System Interface) была образована в IEEE в 1985 г. на основе
UNIX-ориентированного комитета по стандартизации /usr/group (ныне
UniForum). Отсюда видна первоначальная направленность работы
POSIX на стандартизацию интерфейсов ОС UNIX. Однако постепенно
тематика работы рабочих групп POSIX (а со временем их стало
несколько) расширилась настолько, что стало возможным говорить не
о стандартной ОС UNIX, а о POSIX-совместимых операционных средах,
имея в виду любую операционную среду, интерфейсы которых
соответствуют спецификациям POSIX.
Наиболее важной с практической точки зрения является деятельность
рабочей группы POSIX 1003.1 "Интерфейсы системного уровня и их
привязка к языку Си". В документах этой рабочей группы
определяются обязательные интерфейсы между прикладной программой
и операционной системой. С выпуска первой версии этого документа
началась работа POSIX, и он в наибольшей степени связан с ОС
UNIX, хотя в настоящее время интерфейсы 1003.1 поддерживаются в
любой операционной среде, претендующей на соответствие принципам
Открытых Систем.
Из числа прочих рабочих групп упомянем POSIX 1003.2 "Shell и
утилиты", POSIX 1003.3 "Общие методы проверки совместимости с
POSIX", POSIX 1003.4 "Средства, предоставляемые системой для
прикладных программ реального времени", POSIX 1003.5 "Привязка
языка Ада к стандартам POSIX", POSIX 1003.6 "Расширения POSIX,
связанные с безопасностью" и т.д.
Рабочие группы POSIX в настоящее время находятся в ведении IEEE,
и именно этот институт по мере готовности стандартов рекомендует
их к принятию Международной организации по стандартизации (ISO).
Как показывает наличие POSIX 1003.3, POSIX-сообщество справедливо
озабочено проблемой формальной проверки соответствия стандартам
конкретных реализаций. К сожалению, несмотря на наличие целого
ряда соответствующих программных продуктов, проверки носят только
синтаксический характер. Как и большинство современных
программных стандартов, все документы POSIX включают описание
семантики только на неформальном уровне.
Приведенные примеры, конечно, затрагивают лишь небольшую часть
современных программных стандартов. Однако этого достаточно,
чтобы продемонстрировать основную проблему: мы научились (и уже
давно) формально специфицировать синтаксис программных
конструкций, но не умеем на том же уровне простоты
специфицировать их семантику. И дело не в том, что отсутствуют
языки спецификации семантики (например, существует красивый язык
алгебраических спецификаций SDL). Беда в том, что при
использовании любого такого языка семантические спецификации
получаются слишком сложными. Сложность семантической спецификации
программной конструкции приближается к сложности реализации этой
конструкции на языке программирования. Поэтому, в частности,
возникает задача проверки правильности (или отладки?) самих
спецификаций. А на что при этом опираться? Снова на неформальное
описание семантики?
Поэтому, как это не печально, в ближайшем будущем нам придется
принимать на веру заявления производителей программных продуктов
об их соответствии стандартам. Некоторую уверенность может дать
процедура сертификации программного продукта, производимая
авторитетной и независимой организацией. Но и эта уверенность
может быть только относительной, поскольку эксперты, выполняющие
процедуру, тоже опираются на неформальные спецификации семантики.
Программный компромисс относительно иерархий типов
Реализация наследования в Oracle без сомнения значительно улучшает полезность и мощность объектных типов в языке PL/SQL. Означает ли это, что многие и многие разработчики PL/SQL будут теперь использовать преимущества объектных типов и, в частности, эти замечательные новые возможности? У меня есть сомнения на этот счет, и на это - две причины:
Во-первых, многие разработчики и группы разработчиков совершенно счастливы с чисто реляционной моделью. Она делает то, что нужно, она проста, и ей легко управлять как разработчикам, так и администраторам. Конечно, объектная модель имеет некоторые преимущества, но вероятно не такие, чтобы оправдать стоимость дополнительного обучения и изменения мышления, которые потребуются.
Во-вторых, без сомнения, работа с объектной моделью включает написание более сложного кода. Вам придется иметь дело с конструкторами, и другими специальными операторами, типа TREAT, FINAL, SUBSTITUTABLE, и так далее. Вы можете потратить немало времени, чтобы стать профессионалом во всем этом, и потом все же перестать писать код, который является достаточно трудным для понимания и управления.
Итак, прежде всего, рассмотрите, что вам могут дать иерархии объектных типов. Возможно, вы обнаружите, что объектные типы прекрасно вам подходят и имеют важные преимущества. В таком случае, глубоко изучите эти возможности и обеспечьте их использование во всей их мощности. Если вы не видите в этом ничего хорошего, не расстраивайтесь. Просто оставайтесь со своими реляционными таблицами и более простыми структурами данных. Они работали на протяжении 25 лет (юбилей, который Oracle сейчас отмечает); и, вероятно, будут хороши в течение еще долгого времени.
Листинг 1. Попытка указать два приема пищи.
BEGIN INSERT INTO meal VALUES ( SYSDATE, food_t ('Shrimp cocktail', 'PROTEIN', 'Ocean'), food_t ('Eggs benedict', 'PROTEIN', 'Farm'), dessert_t ('Strawberries and cream', 'FRUIT', 'Backyard', 'N', 2001)); INSERT INTO meal VALUES ( SYSDATE + 1, dessert_t ('Strawberries and cream', 'FRUIT', 'Backyard', 'N', 2001), food_t ('Eggs benedict', 'PROTEIN', 'Farm'), cake_t ('Apple Pie', 'FRUIT', 'Baker''s Square', 'N', 2001, 8, NULL)); END;
Листинг 2. Ограничение подставляемости в объектной таблице
SQL> CREATE TABLE brunches OF food_t NOT SUBSTITUTABLE AT ALL LEVELS; Table created. SQL> SQL> INSERT INTO brunches VALUES ( 2 food_t ('Eggs benedict', 'PROTEIN', 'Farm')); 1 row created. SQL> INSERT INTO brunches VALUES ( 2 dessert_t ('Strawberries and cream', 'FRUIT', 'Backyard', 'N', 2001)); dessert_t ('Strawberries and cream', 'FRUIT', 'Backyard', 'N', 2001)) * ERROR at line 2: ORA-00932: inconsistent datatypes
Листинг 3. Вставка записей в таблицу meal.
BEGIN -- Заполнение таблицы meal INSERT INTO meal VALUES ( SYSDATE, food_t ('Shrimp cocktail', 'PROTEIN', 'Ocean'), food_t ('Eggs benedict', 'PROTEIN', 'Farm'), dessert_t ('Strawberries and cream', 'FRUIT', 'Backyard', 'N', 2001)); INSERT INTO meal VALUES ( SYSDATE + 1, food_t ('Shrimp cocktail', 'PROTEIN', 'Ocean'), food_t ('Stir fry tofu', 'PROTEIN', 'Vat'), cake_t ('Apple Pie', 'FRUIT', 'Baker''s Square', 'N', 2001, 8, NULL)); INSERT INTO meal VALUES ( SYSDATE + 1, food_t ('Fried Calamari', 'PROTEIN', 'Ocean'), -- Butter cookies for dinner? Yikes! dessert_t ('Butter cookie', 'CARBOHYDRATE', 'Oven', 'N', 2001), cake_t ('French Silk Pie', 'CARBOHYDRATE', 'Baker''s Square', 'Y', 2001, 6, 'To My Favorite Frenchman')); END; /
Листинг 4. Использование оператора TREAT.
SQL> SELECT TREAT (main_course AS dessert_t).contains_chocolate chocolatey 2 FROM meal 3 WHERE TREAT (main_course AS dessert_t) IS NOT NULL; CHOCOLATEY --------------- N
Пролог
Был выражен пессимизм в отношении связывания Пролога с СУБД. Многие участники считали, что следует прекратить финансировать соответствующие проекты.
Пессимизм, возможно, оправдан, но проекты существуют и в настоящее время.
Просмотр объектов
Разработчики часто добавляют дополнительные возможности в программу используя COM объекты (ActiveX и другие). Но если на объект нет документации и неизвестны его свойства, события и методы, то достаточно сложно использовать его со всей эффективностью. Приложение Object Browser позволяет просматривать свойства и методы объектов.

Рисунок 6. Просмотр объектов
Простейшая иерархия
В качестве примера, возьмем часть схемы подразделений на предприятии:
| A1 | ||
| B1 | B2 | |
| C1 | C2 | C3 |
где А1 - подразделение верхнего уровня (возможно, не единственное на этом уровне),
В1 и В2 - входят в А1,
С1 - входит в В1, С2 и С3 - входят в В2.
Можно легко создать таблицу, которая содержит информацию об этих подразделениях (здесь идалее - синтаксис MS SQL):
create table Departments ( Id int not null identity primary key, Parent int not null references Departments(Id), Name varchar(32) not null )
Поле Parent является ссылкой на Id (первичный ключ) вышестоящего уровня в иерархии. В данном случае оно указывает, в какое подразделение входит каждый отдел.
| Departments | ||
| Id | Parent | Name |
| 1 | 0 | A1 |
| 2 | 1 | B1 |
| 3 | 1 | B2 |
| 4 | 2 | C1 |
| 5 | 3 | C2 |
| 6 | 3 | C3 |
Простота.
Помимо прочих требований, протокол GIOP сделан максимально простым. Его простота допускает возможность реализации взаимодействия по этому протоколу практически в любой системе.
Простота инсталляции.
При инсталляции Cache' происходит автоматическая проверка настроек операционной системы и производится необходимое конфигурирование ресурсов. Так, к примеру, производится автоматическое определение web-сервера, конфигурирование CSP-компонентов и создание необходимых виртуальных директорий.
Минимальные требования к аппаратному обеспечению для работы под ОС Windows:
Процессор Intel Pentium. ОЗУ - 64 Мбайт (минимум). 100 Мбайт свободного места на диске. Сконфигурированный протокол TCP/IP с фиксированным IP-адресом.
Наличие Web-сервера не обязательно. Для тестирования CSP-приложений можно воспользоваться встроенным в СУБД Cache' web-сервером (по умолчанию порт 1972). Однако использование встроенного web-сервера для реальной работы не рекомендуется.
При установке Cache' под Windows-платформами предоставляется возможность выбора одного из следующих вариантов установки:
Standard. Устанавливаются сам сервер БД Cache', ActiveX-компоненты, CSP-компоненты, инструментарий разработки и администрирования СУБД, документация. Client. Устанавливаются клиентские компоненты администрирования и разработки приложений Cache'. Custom. Выборочная установка компонентов СУБД Cache'.
После выбора варианта установки программа инсталляции Cache' запрашивает информацию о размерности кодировки - 8-битовая или Unicode (16 бит). Выбор кодировки целиком и полностью зависит от требований разработчика, однако следует помнить, что Cache' автоматически произведет конвертацию из 8-битовой БД в Unicode БД, однако обратную конвертацию придется производить вручную.
После успешной установки Cache' на панели задач MS Windows появится иконка Cache'-куба


Рис.8. Меню Cache'-куба
Пространственные базы данных
Несколько участников приводили в пример трудно реализуемых приложений те, в которых требуется работа с пространственной информацией (например, картографические приложения). Они считали, что поддержка таких приложений является важной областью применения расширяемых СУБД.
И были правы, поскольку сегодня все развитые системы (например, Oracle, Informix, DB2 и т.д.) поддерживают управление пространственной информацией.
Протокол обмена GIOP.
За исключением редкого случая прямых вызовов методов между классами одного и того же языка программирования необходим механизм кодирования вызова метода в некоторую последовательность байт (byte stream) у клиента и декодирования этой последовательности у сервера. Для этой цели спецификация CORBA определяет Общий Протокол обмена между Брокерами Объектных Запросов (General Inter-Orb Protocol - GIOP). Кроме того, определен протокол передачи сообщений протокола GIOP поверх транспортного протокола TCP/IP, являющегося основным видом взаимодействия в Internet, ввиду чего этот протокол получил название Протокола обмена между Брокерами Объектных в Internet (Internet Inter-Orb Protocol - IIOP). Протокол IIOP должен поддерживаться всеми Брокерами Объектных Запросов независимо от особенностей их реализации, что является главным требованием для обеспечения взаимодействия между произвольными ORB-ами двух разных и совершенно независимых производителей.
Пути интеграции
Процесс интегрирования OLAP-технологии с учетными системами может осуществляться по-разному. Все подходы имеют свои преимущества и недостатки. Как уже было сказано выше, прямая настройка аналитических средств (Direct BI) затруднена. Возможно также создание дублированных баз данных, витрин и Хранилищ данных. Практически всегда возникает необходимость в преобразовании операционных данных в аналитические. Для создания многомерного представления, нужно настроить данные так, чтобы они соответствовали логической многомерной структуре, далекой от структуры учетной системы. Например, многие измерения, используемые для анализа, могут вообще не иметь соответствий в учетных системах и извлекаться из других источников.
R*O и объектно-реляционная модель
Отметим, что основным предположением, на котором основываеться R*O является предположение об ортогональности объектной и реляционной моделей представления данных. Существующая объектно - реляционная модель также основывается на этой посылке. С точки зрения этой модели класс является доменом атрибута отношения. Следует отметить, что R*O не противоречит этому (это следует хотя бы из того, что в R*O определен специальный тип позволяющий сохранять OID объектов в реляционных кортежах). Более того - следует рассматривать это утверждение как равноправную составляющую R*O модели. Таким образом из ортогональности объектной и реляционной моделей данных следует два взаимодополняющих утверждениня:
- отношение является доменом атрибута скалярного(базового) типа класса;
- класс является доменом атрибута отношения.
Соблюдение этих принципов позволяет описать все существующие в системе данные в терминах как объектной так и реляционной моделей рассматривая объект как:
- осмысленную совокупность сущностей опредляющих его связи с другими объектами;
- носителя информации существенной для описания сущностей и связей между ними.
R*O-система
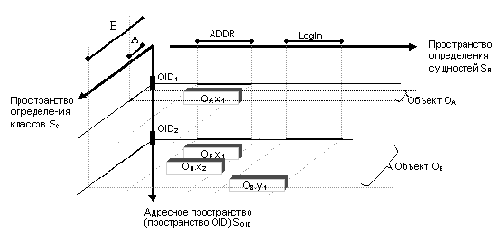
Рис. 4. R*O-система
Проекция этой системы (которая в силу отрогональности R- и O-компонентов автор называет R*O - системой) на плоскость (SC-SOID) дает следующую картину (рис.5)
Рис. 5. O-проекция R*O-системы
(Еще раз необходимо повторить, что пространство определения объектных типов является сложным и многомерным. Однако в любом случае оно может рассматриваться как проекция пространства с большим числом измерений )
Видно что данная проекция является О - системой, где каждый ее элемент (т.е. один из кортежей содержащих информацию об объекте) может быть идентифицирован выражением вида { ( адрес объекта в системе).(положение элемента в схеме (т.е. в классе) описывающей данный объект) }. Поэтому для однозначного определения элементов для каждого из них должна поддерживаться следующая информация.
OID объекта, к которому относится данный элемент;
Информация о положении данного элемента в схеме описывающий класс, к которому данный обьект принадлежит. Каждому полю каждого класса можно поставить в соответствии идентификатор SID (Semantic ID) определяющий семантическое значение этого поля в контексте класса.
Именно эта информация является существенной для того чтобы кортеж мог рассматриваться как осмысленная часть идентифицируемого объекта.
Проекция R*O-системы на плоскость (SR-SOID) будет выглядеть следующим образом (рис.6)

Рис. 6. R-проекция R*O-системы
Пунктирные стрелки показывают что:
каждый элемент принадлежит к тому или иному объекту, имеющему соответствующим OID;
каждый элемент описан как поле класса этого объекта - для каждого элемента существует SID.
Далее будет показано, что эта информация также может быть описана в терминах реляционной модели.
Таким образом реляционная и объектная системы могут быть рассмотрены как ортогональные проекции общей R*O-системы. Можно предположить, что свойства R*O-системы определяются произведением свойств ее проекций. Объект существующий в этой системе является идентифицируемым и осмысленным набором кортежей. Отношение является доменом атрибута скалярного(базового) типа.
Рабочие пространства
Поскольку язык Alpha ориентирован именно на то, чтобы быть подъязыком данных, требуется некоторый механизм для обмена данными с основным языком, в который встраивается Alpha. Для этой цели служат рабочие пространства. Основная идея состоит в том, что данные, выбираемые из базы данных, помещаются в указанное рабочее пространство, в котором они могут быть доступны средствами основного языка; аналогичным образом, данные, генерируемые основным языком, могут быть помещены в такое рабочее пространство и затем пересланы в базу данных посредством другой операции Alpha. Тем самым, с точки зрения Alpha рабочее пространство содержит отношение (или иногда кортеж); с точки зрения основного языка оно содержит передставление такого отношения или кортежа в виде массива (этот "массив" содержит специальную строку с именами столбцов).
Опора Alpha на рабочие пространства, по существу, означает, что язык опирается на концепцию двухуровневого хранения, т.е. пользователь ощущает резкое различие между данными в основной памяти и данными в базе данных. Это различие -- которое, конечно, является следствием того, что Alpha - это именно подъязык данных -- сохранилось во многих других языках, включая SQL. Оно также составляет предмет некоторой критики [6]. В The Third Manifesto мы с Хью Дарвеном полагаем, что пользователи должны иметь оперировать в терминах одноуровневого хранения; пересылка данных между памятью разного уровня является деталью реализации и должна быть сокрыта от пользователя.
Распределенные СУБД
Полагалось, что компании-производители потратят много усилий на развитие области неоднородных (федеративных) распределенных систем баз данных. Увеличение масштабности распределенных баз данных потребует переосмысления алгоритмов обработки запросов, копирования и восстановления после сбоев.
С одной стороны, сегодня все развитые системы поддерживают ограниченные возможности построения неоднородных распределенных баз данных. С другой стороны, эти возможности действительно ограничены, и проблема все еще ожидает своего решения.
Распространенность.
Протоколы GIOP и IIOP разрабатывались с учетом доступного широко распространенного и гибкого транспортного механизма (TCP/IP) и задает минимум дополнительных протоколов, необходимых для передачи запросов между отдельными ORB-ами.
Расширение и сужение объектных типов
Рассмотрим две концепции: расширение и сужение, очень полезные при работе с объектами в иерархии типов, особенно при присваивании переменной или столбцу одного типа объекта другого типа в иерархии. Вот их определение:
Расширение - это присвоение, в котором объявленный тип источника является более конкретным, чем объявленный тип места назначения. Если я присваиваю объект (или экземпляр объектного типа, если говорить точнее) типа cake_t переменной типа dessert_t, то я выполняю расширение. Сужение - это присвоение, в котором объявленный тип источника является более общим, чем объявленный тип места назначения. Если я присваиваю объект типа dessert_t переменной типа cake_t, то я выполняю операцию сужения.
Расширение является фактически "родным" для иерархий объектных типов Oracle и их свойства подставляемости. Любое пирожное является также десертом и едой. Следовательно, до тех пор, пока вы явно не ограничите подставляемость, подтип может трактоваться, храниться и обрабатываться как любой из его супертипов. Вы уже видели несколько примеров этой обработки в статье.
Давайте рассмотрим, как выполняется более сложный шаг - сужение - в SQL и PL/SQL в Oracle9i.
Расширения редактора
Дополнения Foxpro-редактора увеличивают эффективность работы в следующих направлениях:
Выбор пробела или табулятора для выделения текста Настройка строк комментария Поддержка гиперссылок в коде для ссылок на веб-сайты или документацию Поддержка Dirty File Indicator для показа времени внесения изменений в код Быстрая установка точек прерывания в коде Установка закладок для быстрого возврата на нужный фрагмент кода
Расширяемые архитектуры
Участники разделились на два лагеря. Первая часть отдавала предпочтение полнофункциональным СУБД, поддерживающим возможности пользовательских расширений. В то время представителями этого направления были POSTGRES и STARBURST. Представители второго лагеря выступали в пользу инструментальных средств, позволяющих создать требуемую пользователям систему. Примером этого подхода был EXODUS. Мнения разделились почти поровну. Согласие было достигнуто по поводу того, что расширяемые системы являются правильной областью исследований.
Как мы видим сейчас, в большей степени сработал первый подход. На основе POSTGRES через Illustra возник Informix Universal Server, а Starburst явился основой DB2 Universal Database. Вместе с тем, второй подход тоже остается перспективным, и в этом направлении движется, например, компания Sybase.
Расширяемые менеджеры данных
Обсуждение разбилось на два направления - расширяемые архитектуры и объектно-ориентированные базы данных.
Рассмотренные СУБД, пункты обзора и условности.
В следующем разделе приведена информация по СУБД:
Postgres Ingres
Mbase
ONYX
mSQL
Typhoon
LINCKS
Exodus
Информация представлена в следующем виде:
| version: | версия, которая рассматривалась; |
| comment: | несколько общих слов; |
| data model: | модель данных, в том числе поддерживаемые типы; |
| data model: | поддержка режима; |
| client-server: | поддержка режима; |
| access methods: | методы доступа; |
| transaction: | поддержка режима; |
| query lang: | языки запросов, языки доступа; |
| documentation: | наличие, объем и качество документации; |
| disk space: | как СУБД ест disk space; |
| in my mind: | субъективное мнение; |
| где я взял: | источник; |
В пунктах применены следующие условности и сокращения:
| (+) | положительное свойство. |
| (-) | недостаток. |
| (пробовал :) | пробовал, понравилось. |
| (пробовал :( | пробовал, не понравилось (или не работало). |
| (читал :) | читал, порадовался. |
| (читал :( | читал и пробовать не стал. |
Разрешимость
Как я отмечал в аннотации, в [1] утверждается, что в Tutorial D допускается отсутствие разрешимости; более точно, утверждается, что в Tutorial D некоторые логические выражения являются неразрешимыми. Что это значит?
Во-первых, каждое выражение можно считать правилом вычисления значения; поэтому, в частности, логическое выражение можно считать правилом вычисления истинностного значения. Итак, логическое выражение – это выражение, сформулированное на некотором языке L, про которое подразумевается, что оно обозначает TRUE или FALSE. Пусть exp является таким выражением; тогда exp называется неразрешимым, если это выражение правильно построено – т.е. сконструировано в полном соответствии с синтаксическими правилами языка L, – но при этом не существует алгоритм, который за конечное время может определить, является ли результатом вычисления exp TRUE. В расширительном смысле, язык L называется неразрешимым в том и только в том случае, когда существует, по крайней мере, одно неразрешимое выражение, представляемое средствами L. Замечу, между прочим, что исчисление высказываний является разрешимым, а исчисление предикатов – нет.
Если язык L является разрешимым, то по определению существует универсальный алгоритм («разрешающая процедура») для определения за конечное время того, является ли TRUE результатом вычисления произвольного выражения, представленного на языке L. Наоборот, если L является неразрешимым, то такой алгоритм не существует. Более того, если L является неразрешимым, отсутствует даже алгоритм для определения за конечное время того, является ли выражение L разрешимым (если бы такой алгоритм существовал, система могла бы (по крайней мере, частично) избежать проблемы, даже и не пытаясь вычислять неразрешимые выражения).
Из сказанного выше следует, что если, в частности, Tutorial D является неразрешимым, то будут иметься некоторые выражения, представленные с использованием этого языка, и, следовательно, некоторые запросы, представленные на Tutorial D (а именно, запросы, включающие такие выражения), с которыми система не сможет справляться удовлетворительным образом. В связи с этим тот факт, что Tutorial D является неразрешимым, выглядит как серьезный дефект.
